ClickRisorse
Recruiting platform
2025 - now · Product engineering and AI workflow architecture
HR-consulting recruiting platform — a public job board and a consultant back-office, with AI CV parsing and semantic candidate search over a Supabase and pgvector stack.
ClickRisorse: Turning HR Consulting Into a Data-Driven Recruiting Platform
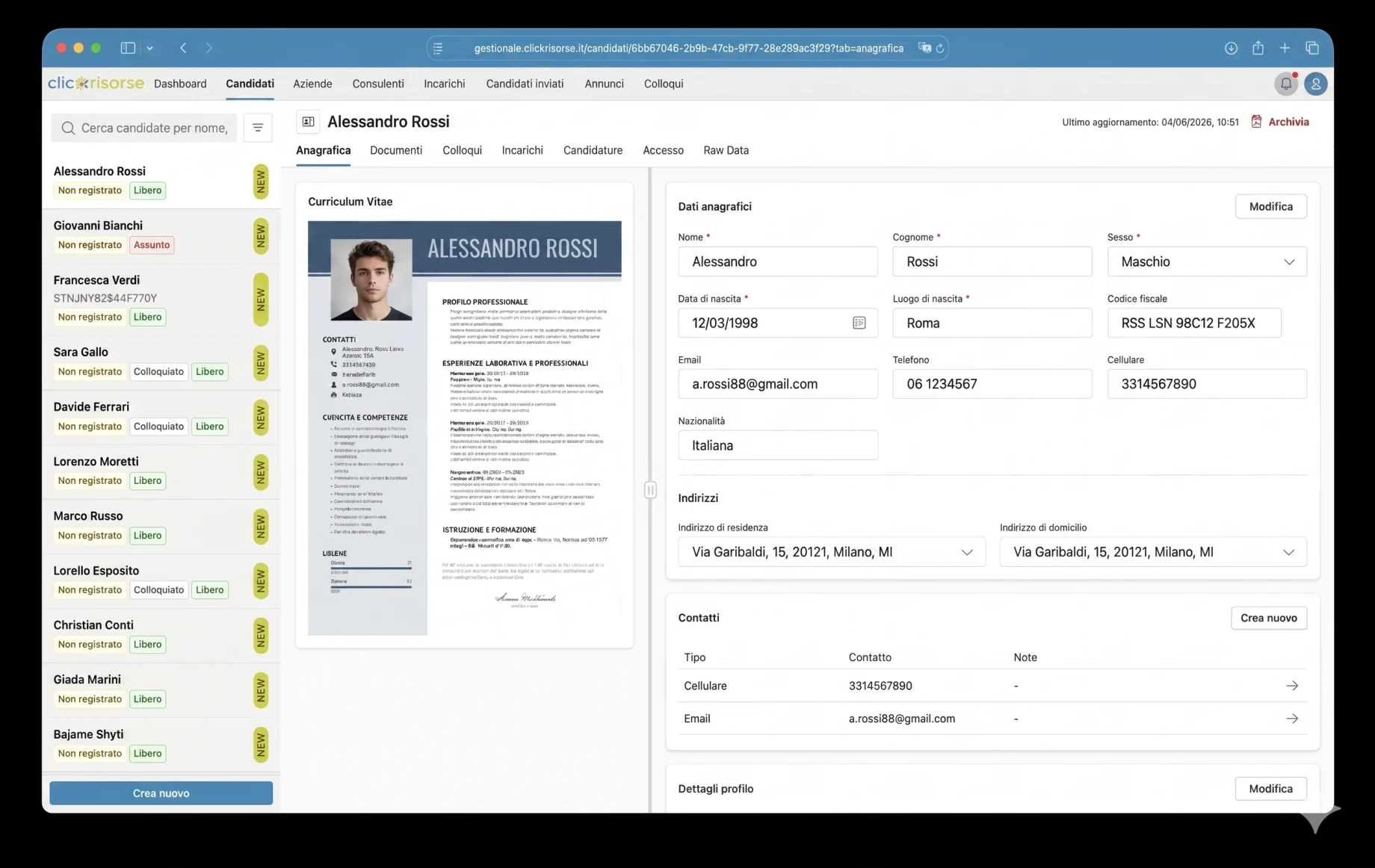
ClickRisorse presents recruiting as a method, not a matter of chance: the right people are selected through continuous support, structured evaluation and a dedicated HR advisor. The platform built for ClickRisorse translates that promise into a full digital operating system for candidates, companies, consultants and internal administrators.
The project is a TurboRepo monorepo built with Vue 3, Vite, TypeScript, Tailwind CSS v4, Pinia and Vue Router. It separates the public job-board experience from the internal management dashboard, while sharing a common UI library based on Fluent UI wrappers, reusable Vue components, design tokens and domain-agnostic form controls.
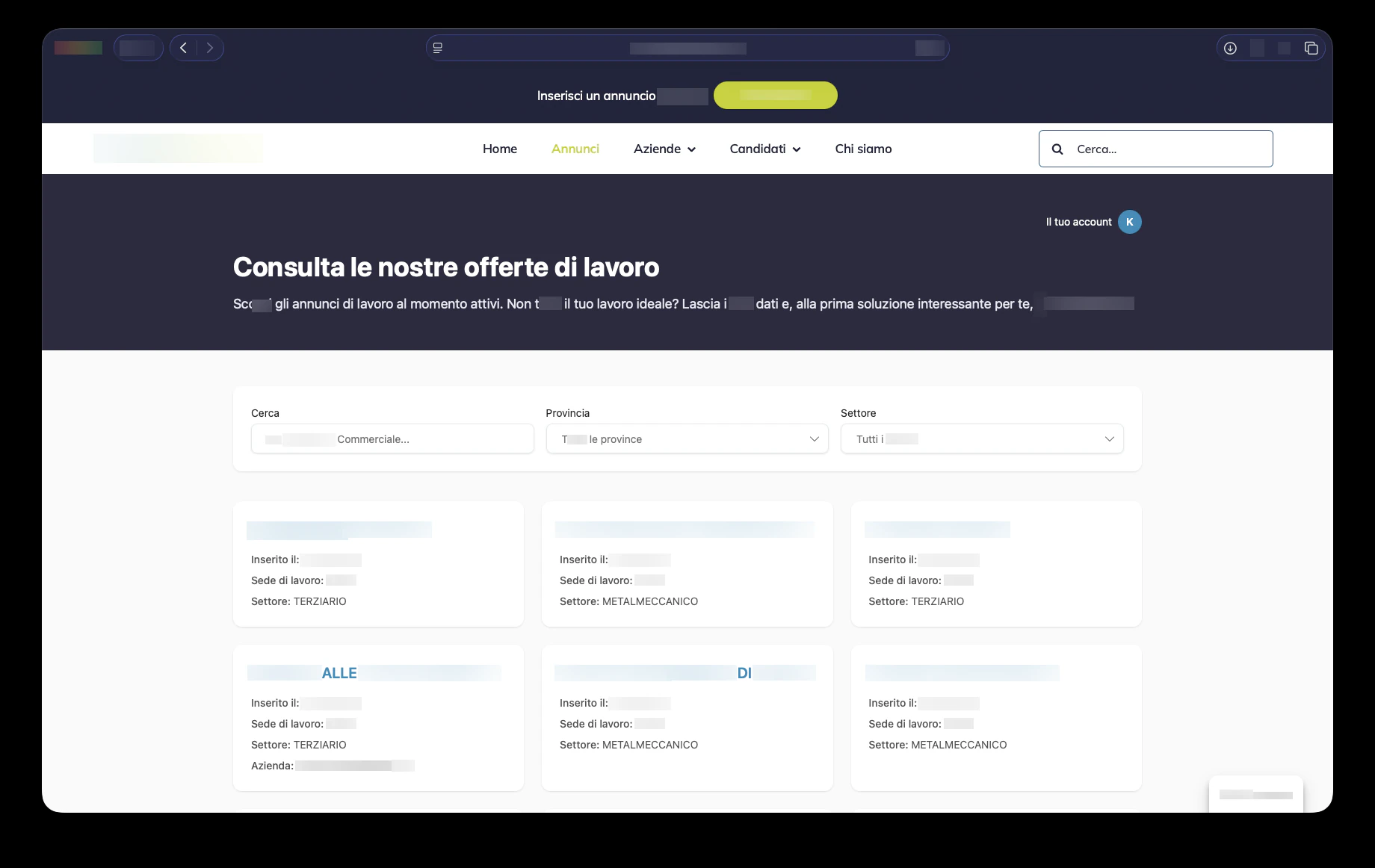
On the public side, candidates can browse active job offers, filter by search term, province and sector, open a detailed job page and apply through a progressive flow. The application process supports CV upload, email verification, Cloudflare Turnstile bot protection, privacy consent and profile reuse. Once a CV is uploaded, the system extracts structured information, lets the candidate review the data, and stores the profile for future opportunities. This directly supports the official ClickRisorse promise: one registration, many applications, with the CV sent again when a suitable opportunity appears.
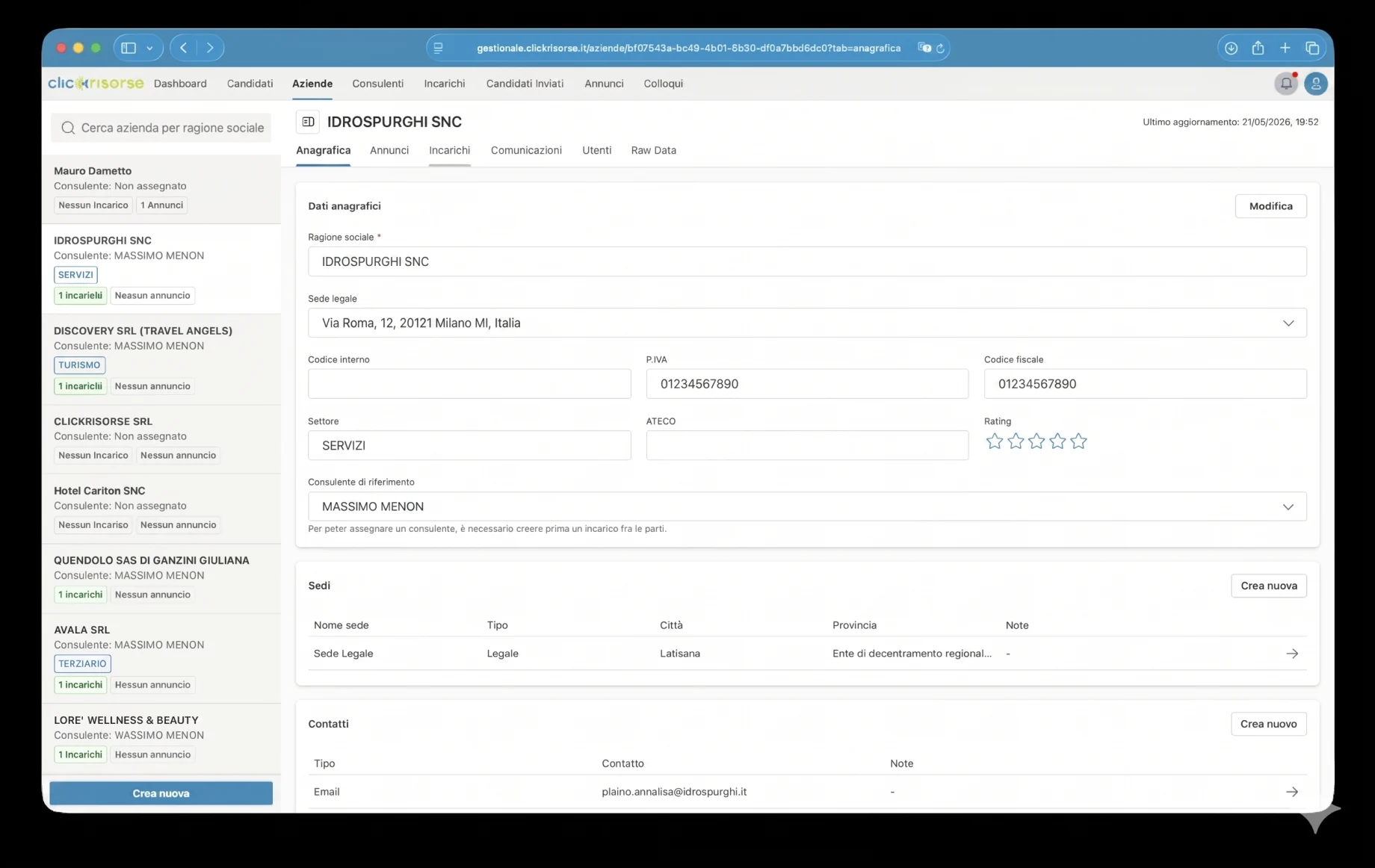
For companies, the platform supports account creation, VAT-number validation, address selection, multiple company locations and role-based company users. It also connects to job posting workflows, matching ClickRisorse’s public offer of simple, autonomous job publication and candidate management.
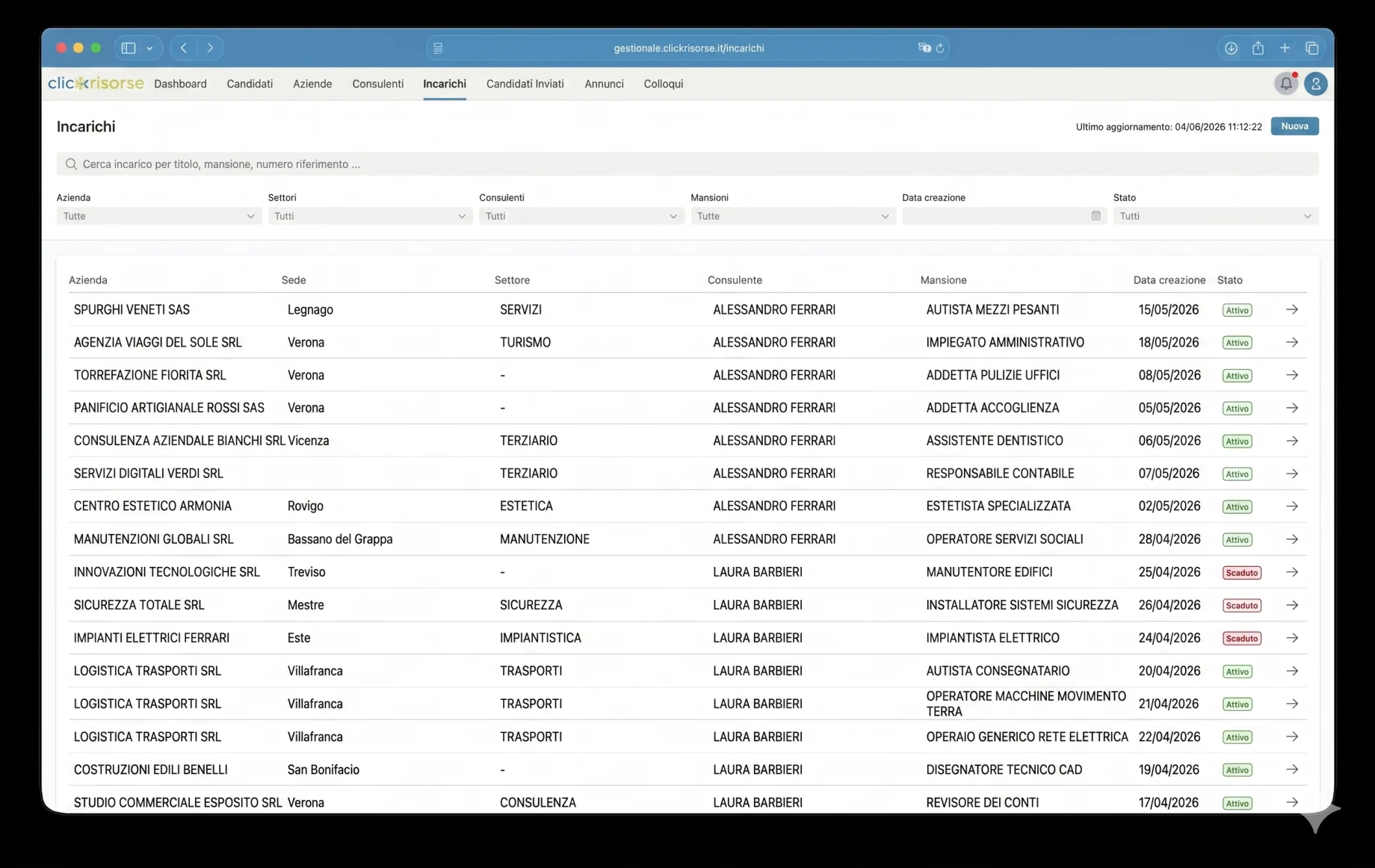
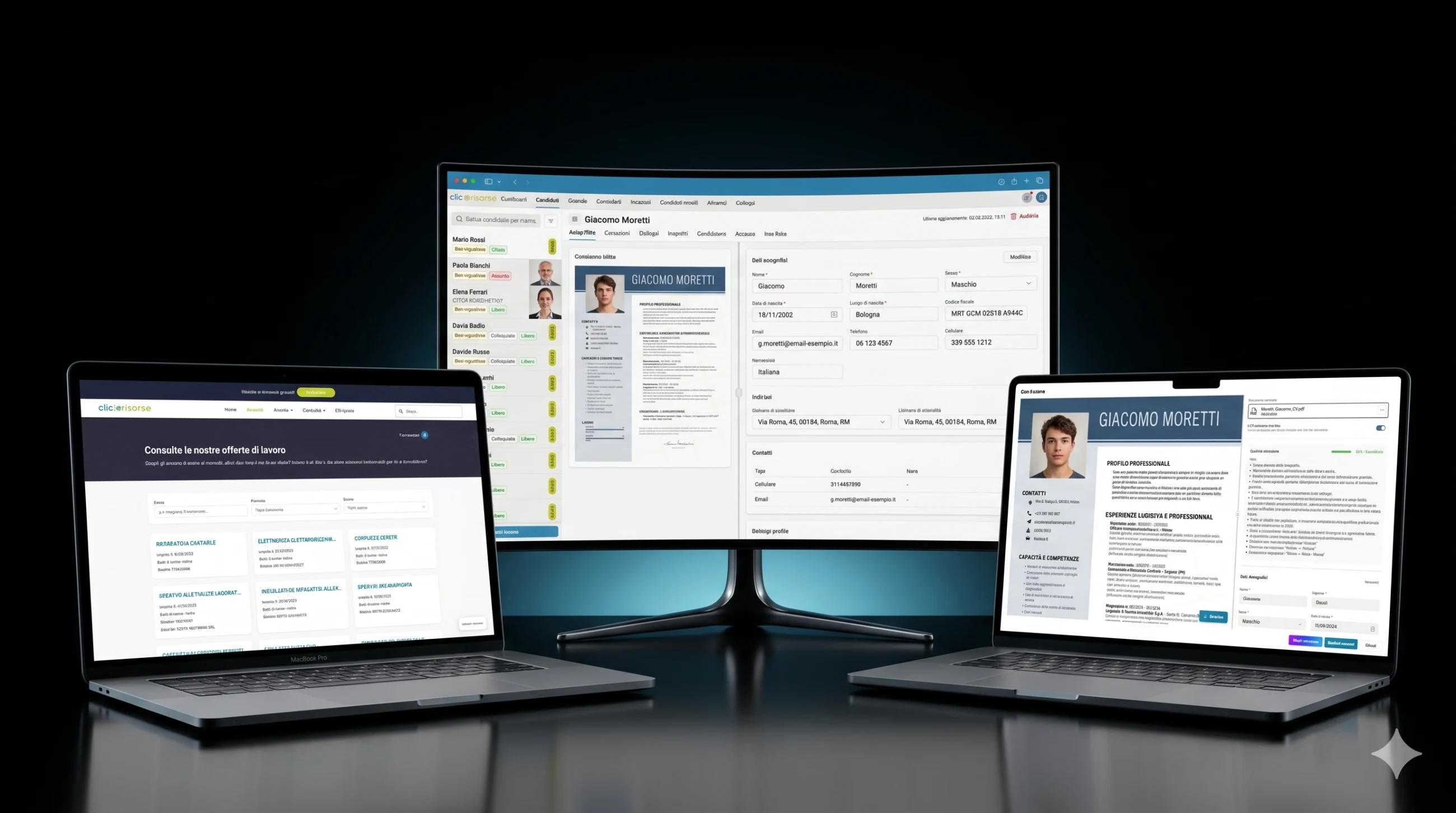
The internal dashboard is where the platform becomes operational. Admins and consultants manage candidates, companies, consultants, users, job ads, assignments, interviews, communications and sent candidates through dense table, drawer and dialog interfaces. The navigation is role-aware: companies see their own areas, consultants access assigned operational views, and admins control the full system. KPI cards, revenue charts, unread communication badges and filtered lists make the dashboard suitable for daily recruiting operations rather than occasional back-office use.
The technical core is Supabase: PostgreSQL, Auth, Storage, Row Level Security, generated database types and Deno Edge Functions. The schema models profiles, roles, permissions, companies, company locations, consultants, candidates, job postings, assignments, interviews, documents, applications, notifications and search executions. Access is governed through RBAC and RLS, with candidates limited to their own profiles and internal candidate data reserved for admins and consultants.
AI is integrated where it improves operational work. CV parsing uses Google Vertex AI/Gemini to extract candidate data, work experience, qualifications, languages and contacts from PDF files. Semantic candidate search uses OpenAI embeddings, pgvector, HNSW indexes and multi-embedding scoring across roles, experience, location and characteristics. An AI assistant helps consultants search candidates in natural language while keeping the UI focused on business terms, not technical parameters.
Deep AI Layer: Reading Heterogeneous CVs and Turning Them Into Searchable Talent Data
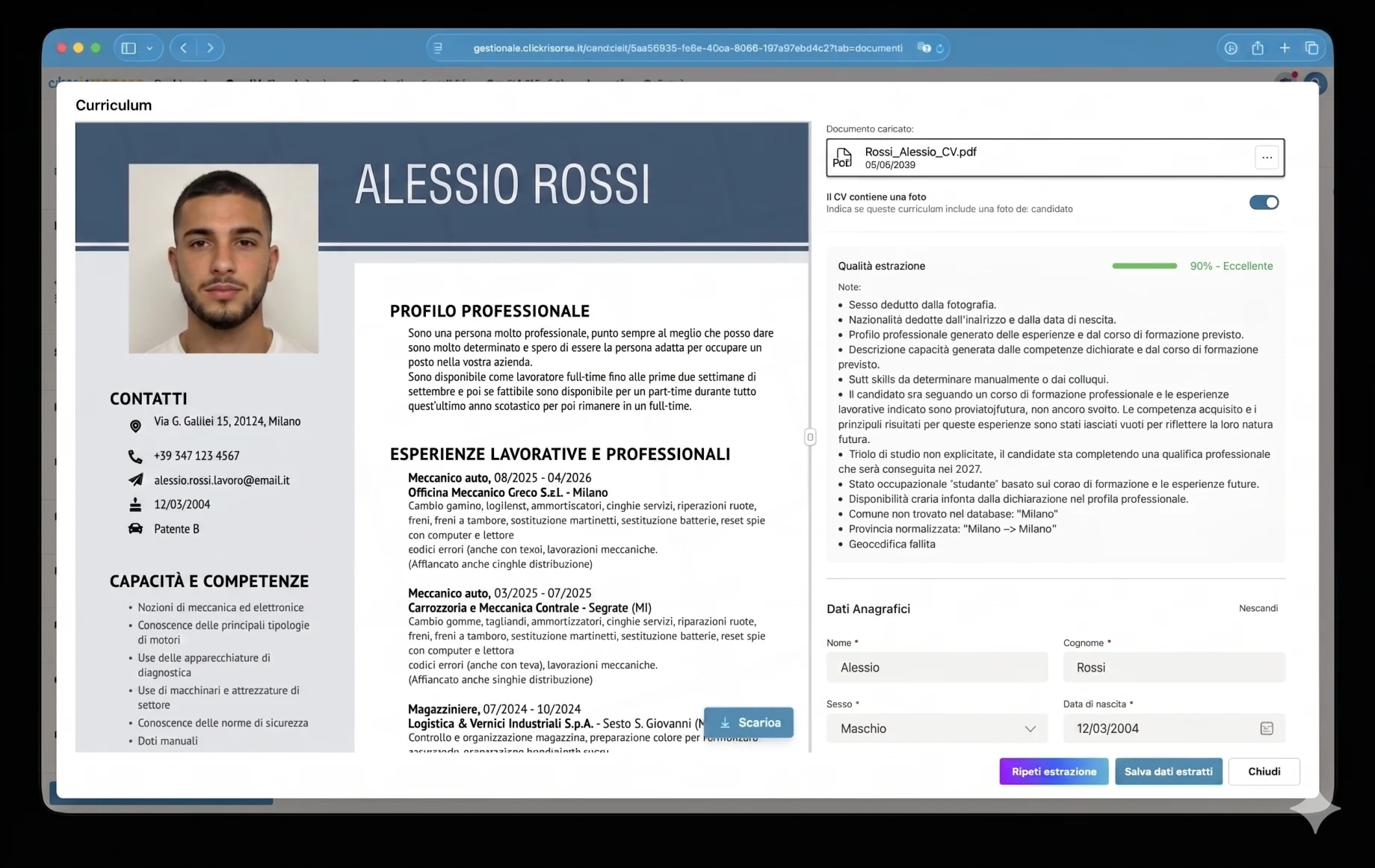
One of the most complex parts of the platform is the AI layer built around candidate CVs. A curriculum is not a standardized document: every PDF arrives with a different structure, visual hierarchy, language, level of detail and quality. Some are clean digital files, others are scanned documents; some include tables, photos, logos, missing dates, inconsistent job titles or self-declared skills that are not supported by actual work experience.
To solve this, the platform uses a domain-tuned extraction pipeline rather than a generic upload form. CVs are processed by specialized AI agents built with strict HR-oriented prompts, structured output schemas and validation rules. The parser uses Google Vertex AI / Gemini for native PDF understanding and OCR, extracting data into a normalized candidate model: personal details, contacts, professional profile, hard skills, work experience, education, certifications, languages, job preferences, availability, mobility and protected-category information.
The extraction is deliberately conservative. The agent is instructed not to invent missing data, to distinguish proven experience from self-declared skills, to translate and normalize text into Italian, and to add extraction notes whenever a field is ambiguous, inferred or missing. For example, a forklift license, HACCP certification or driving license can be treated as a searchable qualification, while a course with no matching work experience is recorded with more caution. This makes the output useful for recruitment, not just text extraction.
Every parsed CV receives an extraction_confidence score from 0 to 1. This becomes a traffic-light quality system in the interface: excellent, good, fair, poor or very poor extraction. Low-quality documents can be rejected before storage, while usable documents are shown to the operator or candidate in a review screen where extracted fields can be corrected before saving. The system also records extraction notes, detects whether the CV includes a candidate photo, normalizes addresses against Italian administrative divisions, and geocodes locations through Google Maps for geographic matching.
Once the CV is transformed into structured data, it feeds a retrieval layer designed specifically for recruiting. Instead of generating one generic embedding for the whole candidate, the platform groups useful information into four semantic retrieval blocks: roles and skills, work experience, location, and personal/work characteristics. These chunks aggregate CV data with later operational signals such as interview notes, consultant evaluations, hard-skill assessments and soft-skill observations.
This creates a RAG-style matching layer for advanced search. Google Vertex gemini-embedding-2 generates 3072-dimensional embeddings for each semantic block, stored in PostgreSQL/pgvector as optimized vectors with HNSW indexes. Recruiters can then search in natural language, while the system compares different dimensions separately: job relevance, seniority, geographic fit and contextual constraints. The result is not a keyword search over uploaded PDFs, but a structured talent index built from heterogeneous documents, human review and AI-enriched recruitment knowledge.
The screenshots shown are anonymized: real candidate names, contacts and CV details have been replaced with fictitious data.
Gallery