ClickRisorse
Платформа для рекрутингу
2025 - now · Продуктова розробка та архітектура AI-процесів
Платформа для рекрутингу у сфері HR-консалтингу — публічна дошка вакансій і бек-офіс для консультантів, з AI-розбором резюме та семантичним пошуком кандидатів на стеку Supabase і pgvector.
ClickRisorse: перетворення HR-консалтингу на платформу для рекрутингу, засновану на даних
ClickRisorse представляє рекрутинг як метод, а не як справу випадку: правильні люди добираються завдяки постійній підтримці, структурованому оцінюванню та виділеному HR-консультанту. Платформа, створена для ClickRisorse, перекладає цю обіцянку в повноцінну цифрову операційну систему для кандидатів, компаній, консультантів і внутрішніх адміністраторів.
Проєкт є монорепозиторієм TurboRepo, побудованим на Vue 3, Vite, TypeScript, Tailwind CSS v4, Pinia і Vue Router. Він розділяє публічний досвід дошки вакансій і внутрішню панель керування, водночас спільно використовуючи загальну UI-бібліотеку на основі обгорток Fluent UI, повторно використовуваних компонентів Vue, дизайн-токенів і незалежних від домену елементів форм.
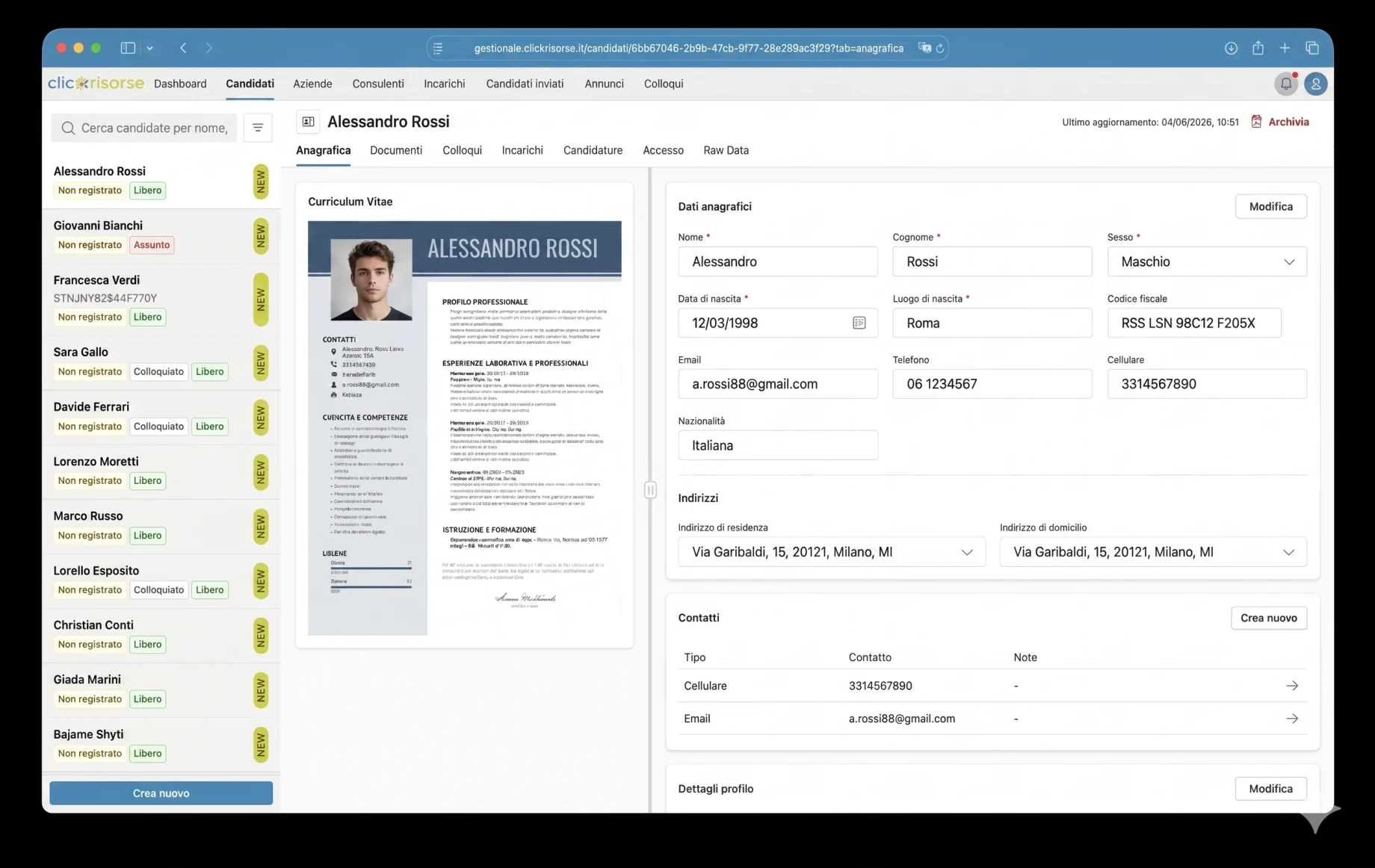
На публічному боці кандидати можуть переглядати активні вакансії, фільтрувати їх за пошуковим запитом, провінцією та сектором, відкривати детальну сторінку вакансії та подавати заявку через поетапний процес. Процес подання заявки підтримує завантаження резюме, підтвердження електронної пошти, захист від ботів Cloudflare Turnstile, згоду на обробку даних і повторне використання профілю. Після завантаження резюме система витягує структуровану інформацію, дозволяє кандидату переглянути дані та зберігає профіль для майбутніх можливостей. Це безпосередньо підтримує офіційну обіцянку ClickRisorse: одна реєстрація, багато заявок, з повторним надсиланням резюме, коли з’являється відповідна можливість.
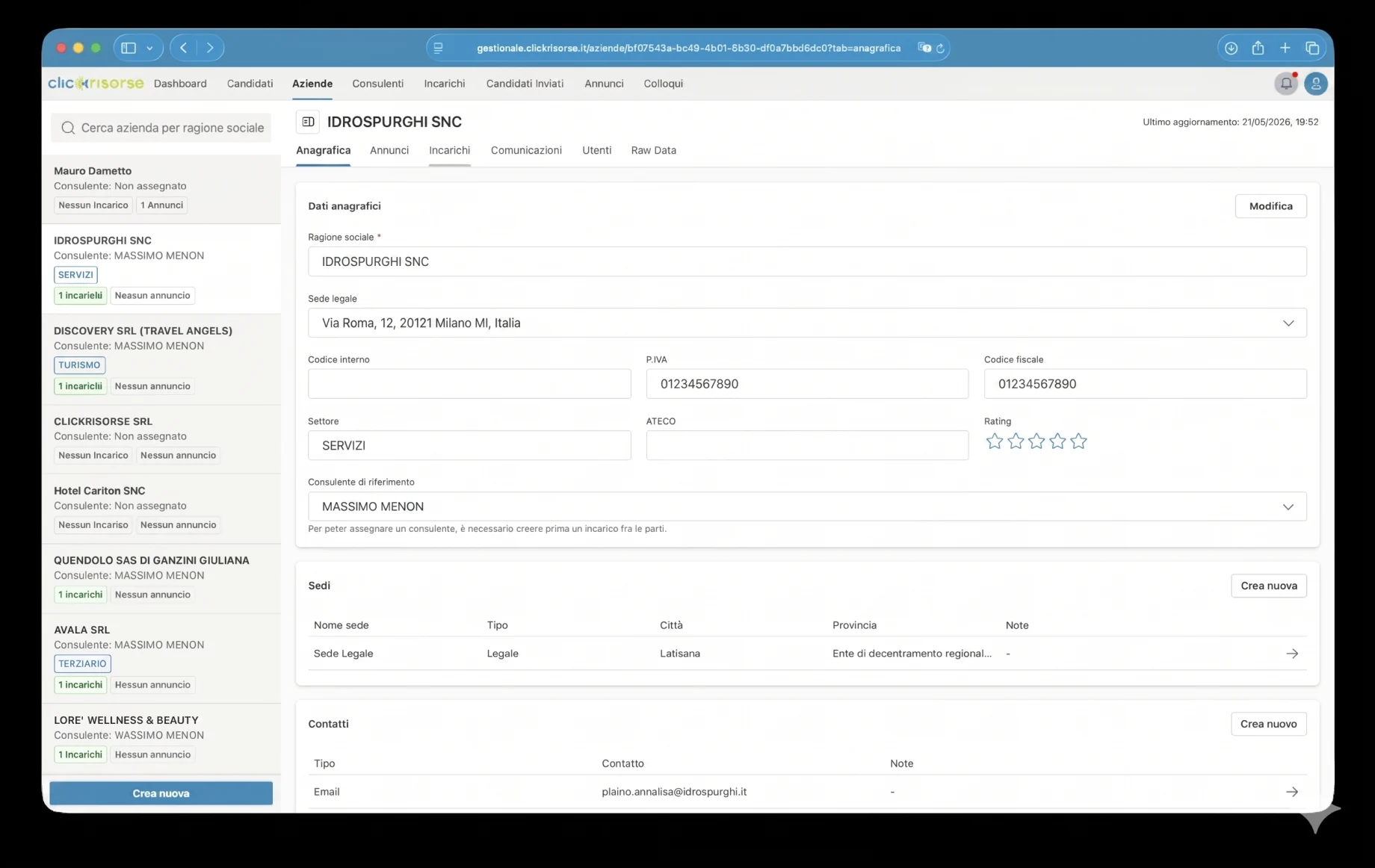
Для компаній платформа підтримує створення облікового запису, перевірку номера ПДВ, вибір адреси, кілька локацій компанії та користувачів компанії з ролями. Вона також підключається до процесів публікації вакансій, що відповідає публічній пропозиції ClickRisorse щодо простої та самостійної публікації вакансій і керування кандидатами.
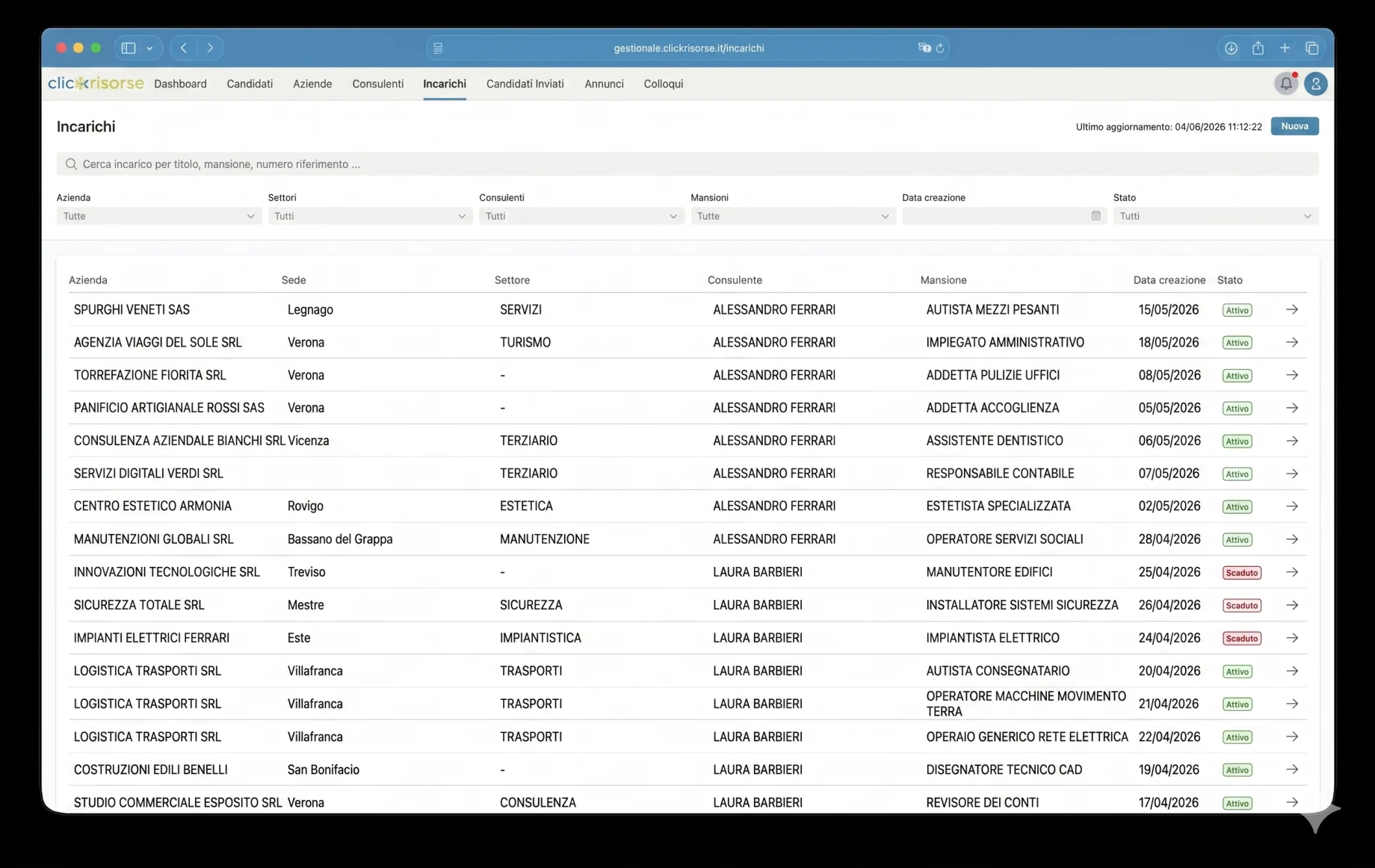
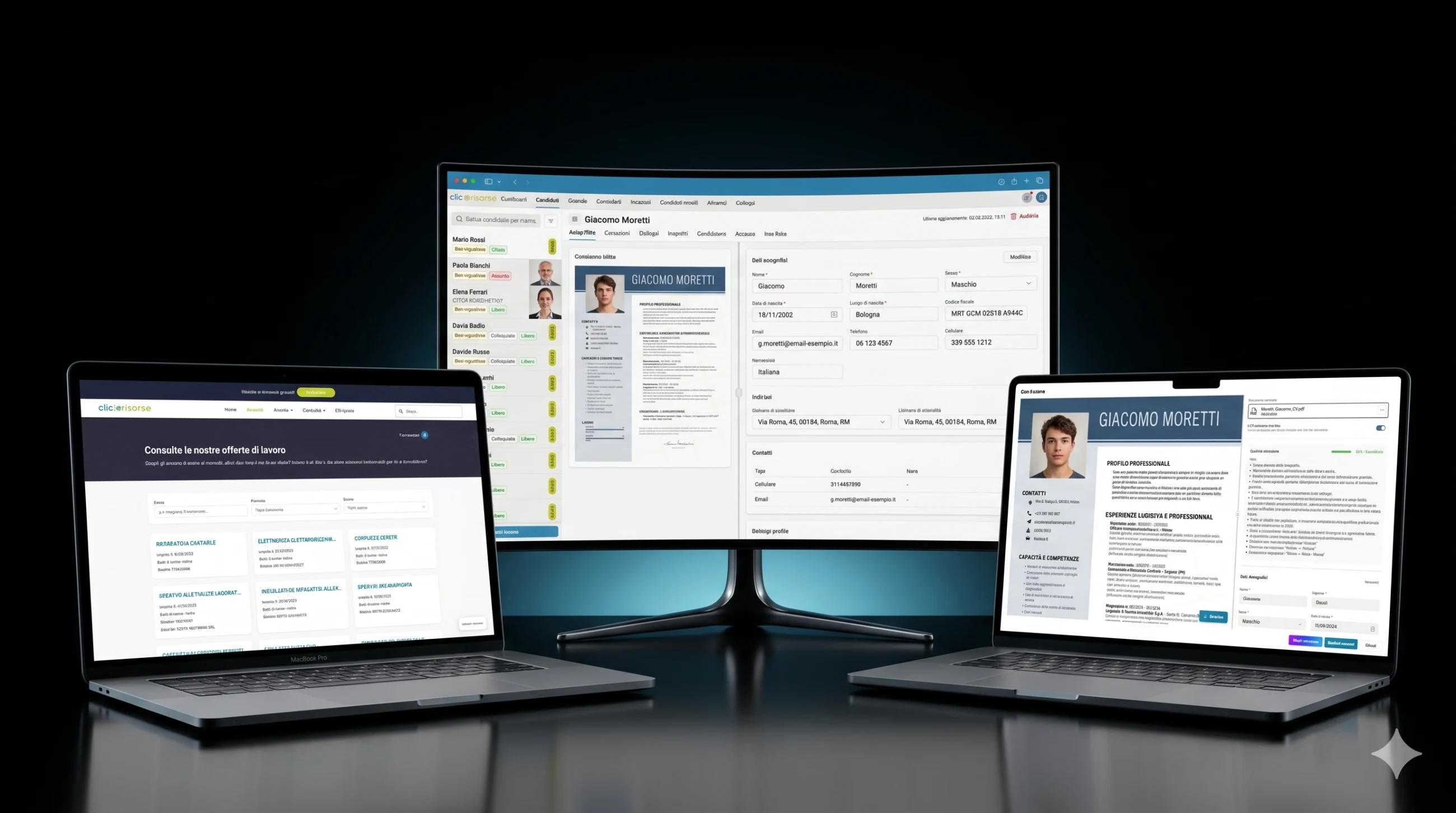
Внутрішня панель керування — це місце, де платформа стає операційною. Адміністратори та консультанти керують кандидатами, компаніями, консультантами, користувачами, оголошеннями про вакансії, призначеннями, співбесідами, комунікаціями та надісланими кандидатами через насичені інтерфейси таблиць, висувних панелей і діалогів. Навігація враховує ролі: компанії бачать свої власні зони, консультанти отримують доступ до призначених операційних подань, а адміністратори керують усією системою. Картки KPI, графіки доходів, бейджі непрочитаних комунікацій і відфільтровані списки роблять панель придатною для щоденних операцій рекрутингу, а не для епізодичного використання бек-офісу.
Технічною основою є Supabase: PostgreSQL, Auth, Storage, Row Level Security, згенеровані типи бази даних і Deno Edge Functions. Схема моделює профілі, ролі, дозволи, компанії, локації компаній, консультантів, кандидатів, вакансії, призначення, співбесіди, документи, заявки, сповіщення та виконання пошуку. Доступ керується через RBAC і RLS, при цьому кандидати обмежені своїми власними профілями, а внутрішні дані про кандидатів зарезервовані для адміністраторів і консультантів.
AI інтегровано там, де він покращує операційну роботу. Розбір резюме використовує Google Vertex AI/Gemini для витягування з PDF-файлів даних кандидата, досвіду роботи, кваліфікацій, мов і контактів. Семантичний пошук кандидатів використовує ембединги OpenAI, pgvector, індекси HNSW і багатоембедингове оцінювання за ролями, досвідом, місцем розташування та характеристиками. AI-асистент допомагає консультантам шукати кандидатів природною мовою, зберігаючи інтерфейс сфокусованим на бізнес-термінах, а не на технічних параметрах.
Глибокий AI-шар: читання різнорідних резюме та перетворення їх на дані про таланти, доступні для пошуку
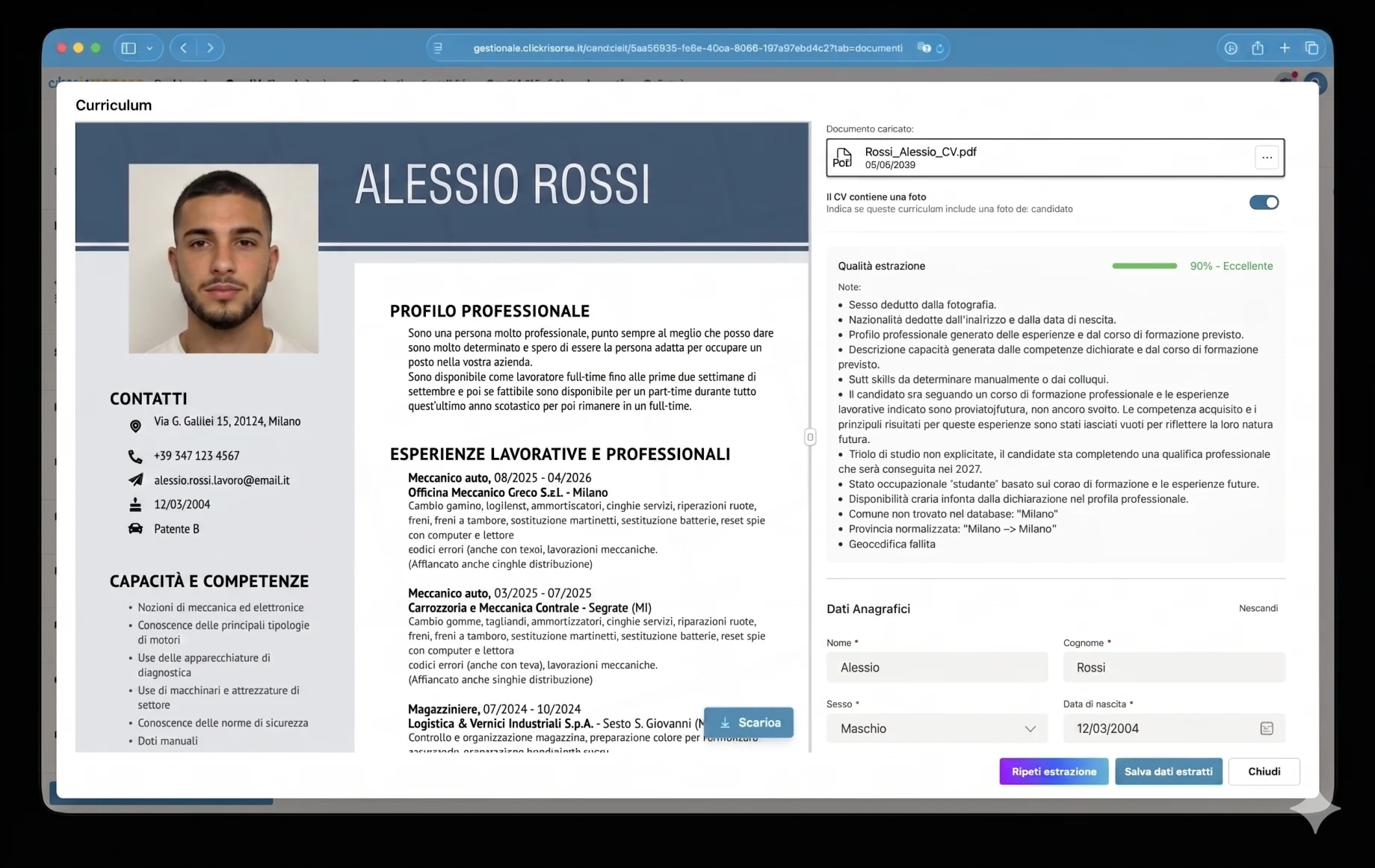
Одна з найскладніших частин платформи — це AI-шар, побудований навколо резюме кандидатів. Резюме не є стандартизованим документом: кожен PDF надходить із різною структурою, візуальною ієрархією, мовою, рівнем деталізації та якістю. Одні — це чисті цифрові файли, інші — відскановані документи; деякі містять таблиці, фотографії, логотипи, відсутні дати, неузгоджені назви посад або самостійно заявлені навички, не підтверджені реальним досвідом роботи.
Щоб вирішити це, платформа використовує налаштований під домен конвеєр витягування, а не універсальну форму завантаження. Резюме обробляються спеціалізованими AI-агентами, побудованими на суворих HR-орієнтованих промптах, структурованих схемах виводу та правилах валідації. Парсер використовує Google Vertex AI / Gemini для нативного розуміння PDF і OCR, витягуючи дані в нормалізовану модель кандидата: персональні дані, контакти, професійний профіль, тверді навички, досвід роботи, освіту, сертифікати, мови, уподобання щодо роботи, доступність, мобільність та інформацію про захищені категорії.
Витягування навмисно консервативне. Агенту вказано не вигадувати відсутні дані, відрізняти підтверджений досвід від самостійно заявлених навичок, перекладати та нормалізувати текст італійською мовою і додавати нотатки про витягування щоразу, коли поле неоднозначне, виведене або відсутнє. Наприклад, посвідчення водія навантажувача, сертифікат HACCP або водійське посвідчення можуть розглядатися як кваліфікація, доступна для пошуку, тоді як курс без відповідного досвіду роботи фіксується з більшою обережністю. Це робить результат корисним для рекрутингу, а не просто витягуванням тексту.
Кожне розібране резюме отримує оцінку extraction_confidence від 0 до 1. В інтерфейсі це перетворюється на систему якості за принципом світлофора: відмінне, добре, задовільне, погане або дуже погане витягування. Документи низької якості можуть бути відхилені до збереження, тоді як придатні документи показуються оператору або кандидату на екрані перевірки, де витягнуті поля можна виправити перед збереженням. Система також фіксує нотатки про витягування, визначає, чи містить резюме фотографію кандидата, нормалізує адреси за італійськими адміністративними одиницями та виконує геокодування місць розташування через Google Maps для географічного зіставлення.
Після того як резюме перетворено на структуровані дані, воно живить шар пошуку, спроєктований спеціально для рекрутингу. Замість генерації одного універсального ембедингу для всього кандидата платформа групує корисну інформацію в чотири семантичні пошукові блоки: ролі та навички, досвід роботи, місце розташування та особисті/робочі характеристики. Ці фрагменти об’єднують дані резюме з подальшими операційними сигналами, такими як нотатки співбесід, оцінки консультантів, оцінки твердих навичок і спостереження за м’якими навичками.
Це створює шар зіставлення в стилі RAG для розширеного пошуку. Google Vertex gemini-embedding-2 генерує 3072-вимірні ембединги для кожного семантичного блоку, що зберігаються в PostgreSQL/pgvector у вигляді оптимізованих векторів з індексами HNSW. Потім рекрутери можуть шукати природною мовою, а система окремо порівнює різні виміри: релевантність ролі, рівень, географічну відповідність і контекстні обмеження. Результат — це не пошук за ключовими словами по завантажених PDF, а структурований індекс талантів, побудований із різнорідних документів, перевірки людиною та збагачених AI знань про рекрутинг.
Показані скриншоти анонімізовано: реальні імена кандидатів, контакти та деталі резюме замінено вигаданими даними.
Галерея