ClickRisorse
Платформа для рекрутинга
2025 - now · Продуктовая разработка и архитектура AI-процессов
Платформа для рекрутинга в сфере HR-консалтинга — публичная доска вакансий и бэк-офис для консультантов, с AI-разбором резюме и семантическим поиском кандидатов на стеке Supabase и pgvector.
ClickRisorse: превращение HR-консалтинга в платформу для рекрутинга, основанную на данных
ClickRisorse представляет рекрутинг как метод, а не как дело случая: правильные люди отбираются благодаря постоянной поддержке, структурированной оценке и выделенному HR-консультанту. Платформа, созданная для ClickRisorse, переводит это обещание в полноценную цифровую операционную систему для кандидатов, компаний, консультантов и внутренних администраторов.
Проект представляет собой монорепозиторий TurboRepo, построенный на Vue 3, Vite, TypeScript, Tailwind CSS v4, Pinia и Vue Router. Он разделяет публичный опыт доски вакансий и внутреннюю панель управления, при этом разделяя общую UI-библиотеку на основе обёрток Fluent UI, переиспользуемых компонентов Vue, дизайн-токенов и независимых от домена элементов форм.
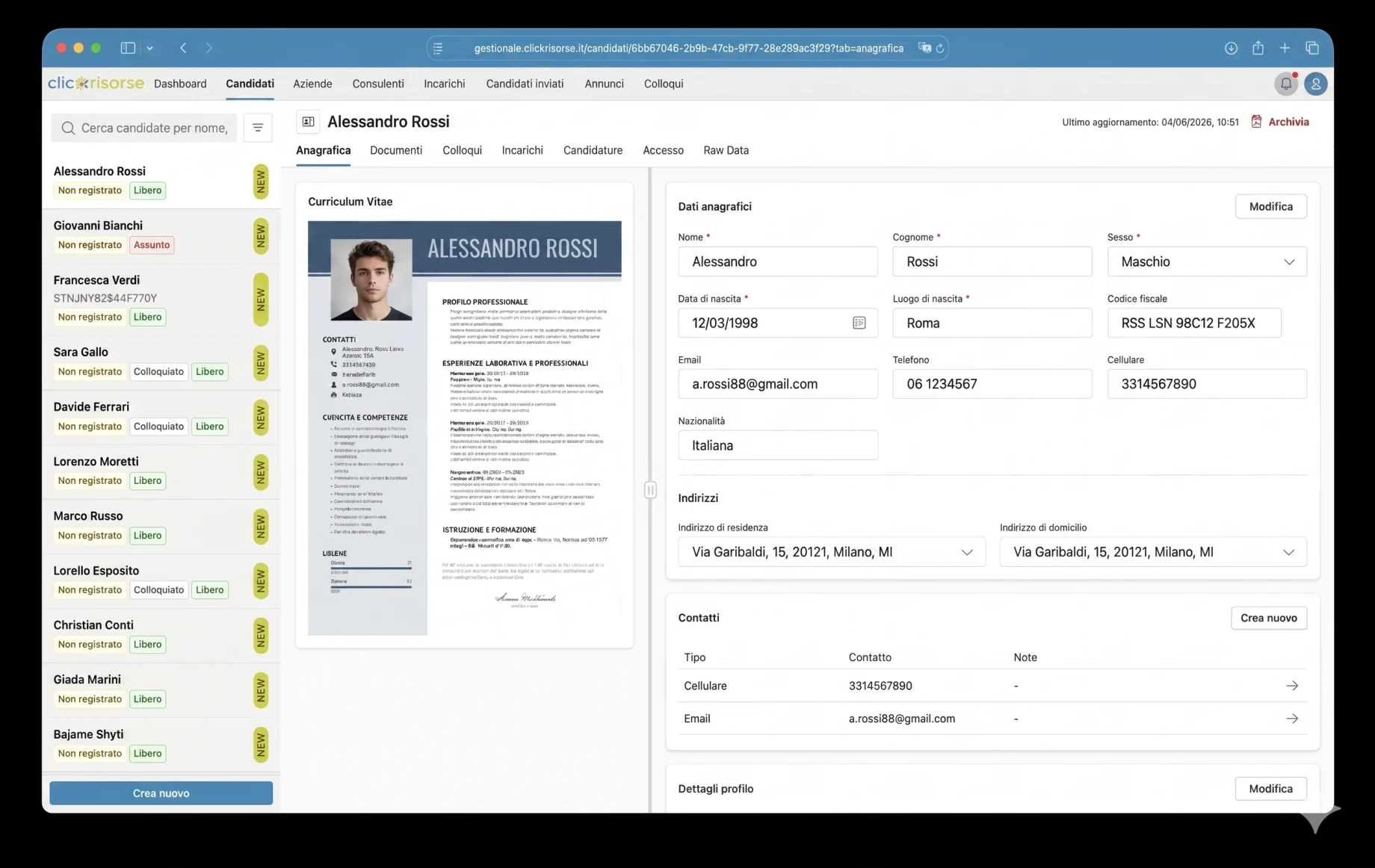
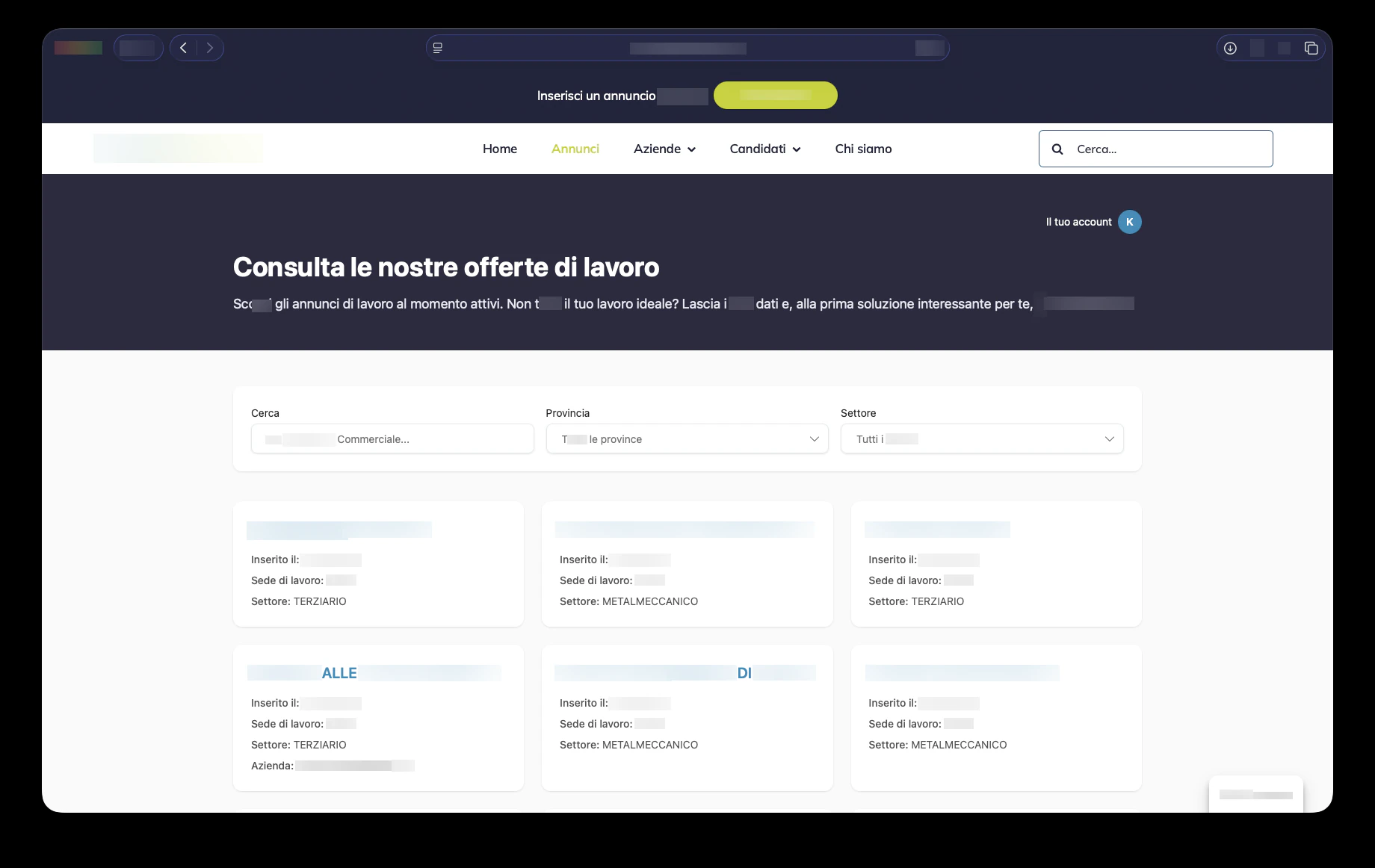
На публичной стороне кандидаты могут просматривать активные вакансии, фильтровать их по поисковому запросу, провинции и сектору, открывать подробную страницу вакансии и откликаться через пошаговый процесс. Процесс отклика поддерживает загрузку резюме, подтверждение электронной почты, защиту от ботов Cloudflare Turnstile, согласие на обработку данных и повторное использование профиля. После загрузки резюме система извлекает структурированную информацию, позволяет кандидату проверить данные и сохраняет профиль для будущих возможностей. Это напрямую поддерживает официальное обещание ClickRisorse: одна регистрация, множество откликов, с повторной отправкой резюме при появлении подходящей возможности.
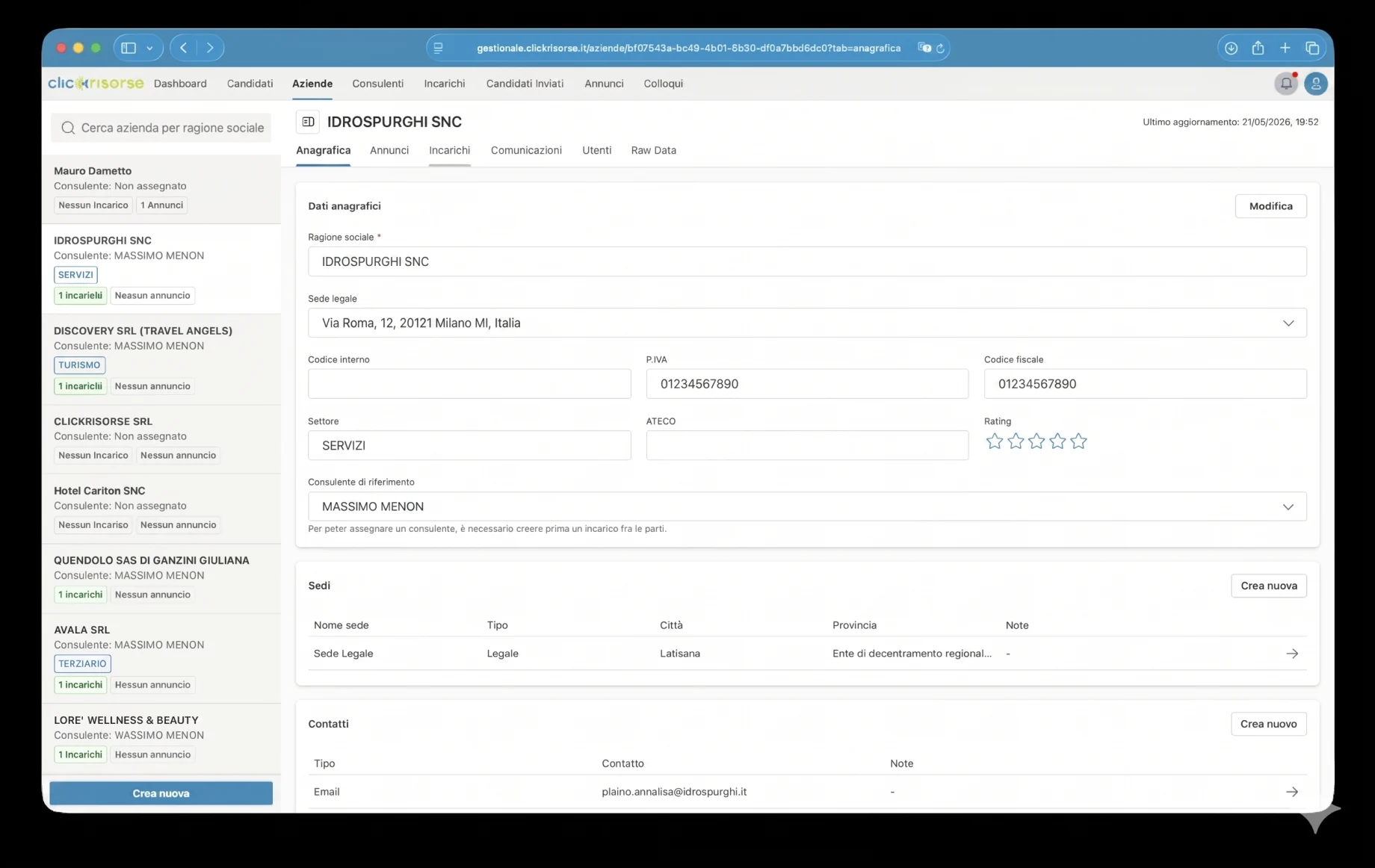
Для компаний платформа поддерживает создание учётной записи, проверку номера НДС, выбор адреса, несколько локаций компании и пользователей компании с ролями. Она также подключается к процессам публикации вакансий, что соответствует публичному предложению ClickRisorse о простой и самостоятельной публикации вакансий и управлении кандидатами.
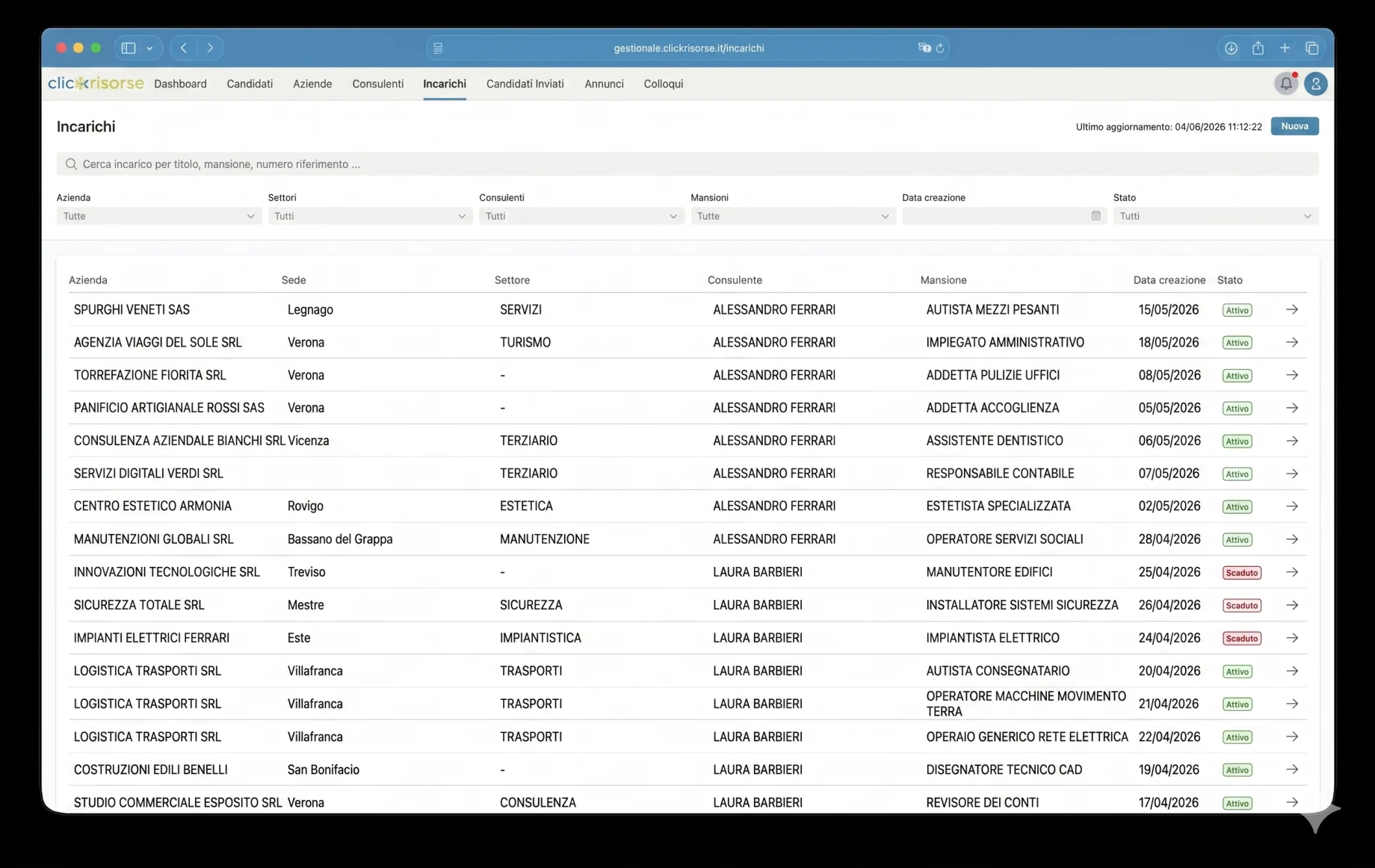
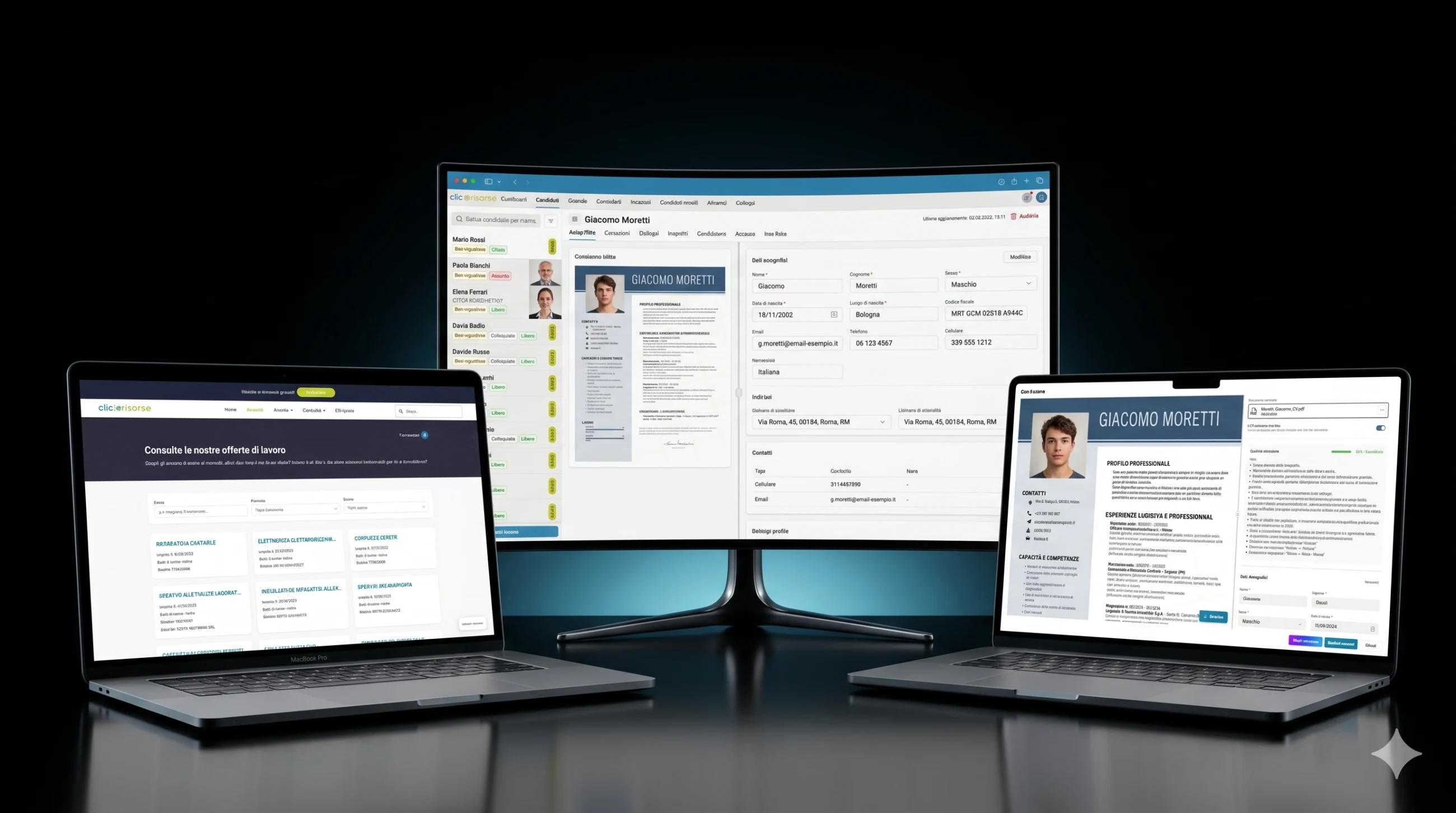
Внутренняя панель управления — это место, где платформа становится операционной. Администраторы и консультанты управляют кандидатами, компаниями, консультантами, пользователями, объявлениями о вакансиях, назначениями, собеседованиями, коммуникациями и отправленными кандидатами через насыщенные интерфейсы таблиц, выдвижных панелей и диалогов. Навигация учитывает роли: компании видят свои собственные области, консультанты получают доступ к назначенным операционным представлениям, а администраторы управляют всей системой. Карточки KPI, графики выручки, бейджи непрочитанных коммуникаций и отфильтрованные списки делают панель пригодной для ежедневных операций рекрутинга, а не для эпизодического использования бэк-офиса.
Технической основой является Supabase: PostgreSQL, Auth, Storage, Row Level Security, сгенерированные типы базы данных и Deno Edge Functions. Схема моделирует профили, роли, разрешения, компании, локации компаний, консультантов, кандидатов, вакансии, назначения, собеседования, документы, отклики, уведомления и выполнения поиска. Доступ управляется через RBAC и RLS, при этом кандидаты ограничены своими собственными профилями, а внутренние данные о кандидатах зарезервированы для администраторов и консультантов.
AI интегрирован там, где он улучшает операционную работу. Разбор резюме использует Google Vertex AI/Gemini для извлечения из PDF-файлов данных кандидата, опыта работы, квалификаций, языков и контактов. Семантический поиск кандидатов использует эмбеддинги OpenAI, pgvector, индексы HNSW и многоэмбеддинговую оценку по ролям, опыту, местоположению и характеристикам. AI-ассистент помогает консультантам искать кандидатов на естественном языке, сохраняя интерфейс сфокусированным на бизнес-терминах, а не на технических параметрах.
Глубокий AI-слой: чтение разнородных резюме и превращение их в данные о талантах, доступные для поиска
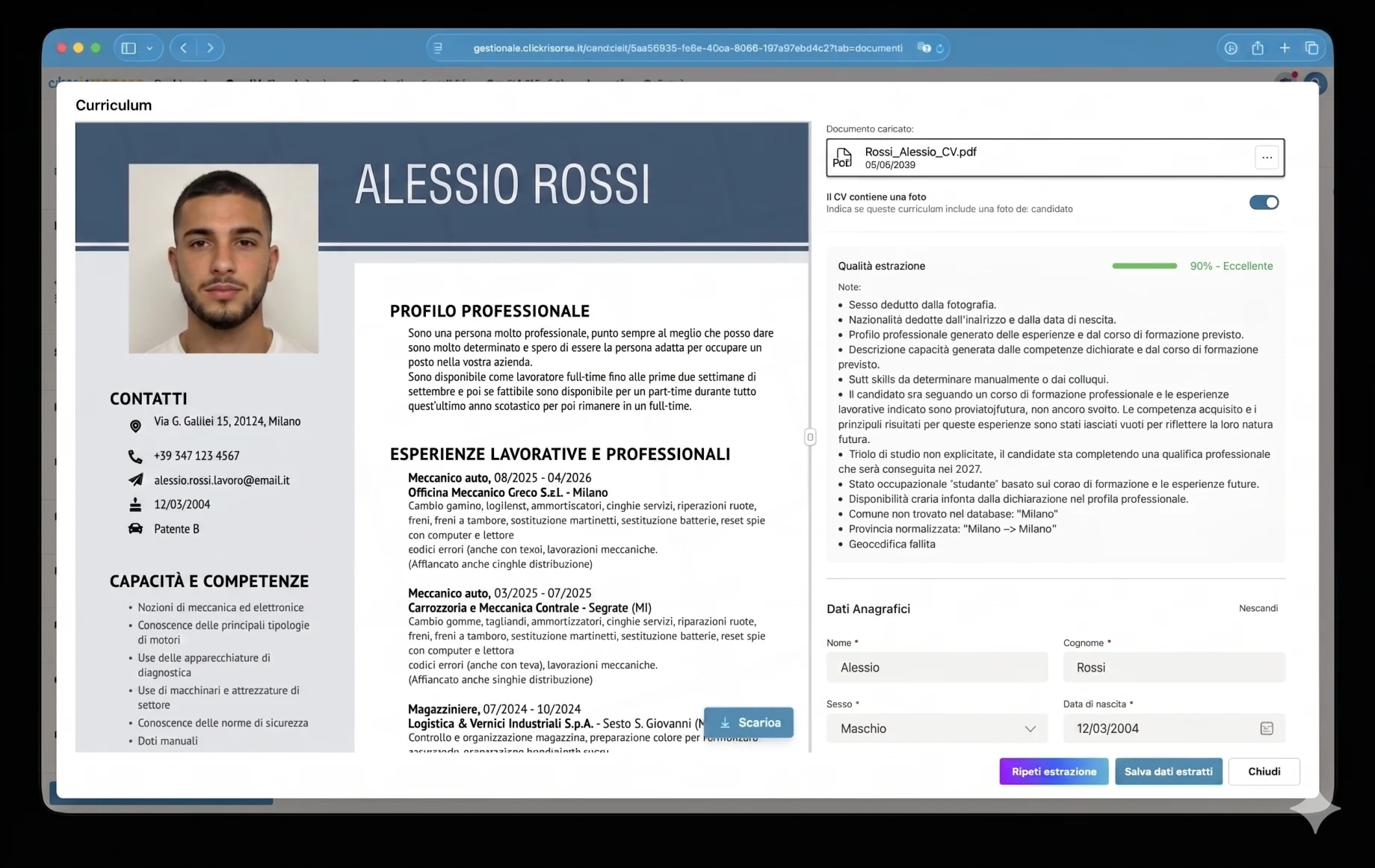
Одна из самых сложных частей платформы — это AI-слой, построенный вокруг резюме кандидатов. Резюме не является стандартизированным документом: каждый PDF приходит с разной структурой, визуальной иерархией, языком, уровнем детализации и качеством. Одни — это чистые цифровые файлы, другие — отсканированные документы; некоторые содержат таблицы, фотографии, логотипы, отсутствующие даты, несогласованные названия должностей или заявленные самостоятельно навыки, не подтверждённые реальным опытом работы.
Чтобы решить эту задачу, платформа использует настроенный под домен конвейер извлечения, а не универсальную форму загрузки. Резюме обрабатываются специализированными AI-агентами, построенными на строгих HR-ориентированных промптах, структурированных схемах вывода и правилах валидации. Парсер использует Google Vertex AI / Gemini для нативного понимания PDF и OCR, извлекая данные в нормализованную модель кандидата: персональные данные, контакты, профессиональный профиль, твёрдые навыки, опыт работы, образование, сертификаты, языки, предпочтения по работе, доступность, мобильность и информацию о защищённых категориях.
Извлечение намеренно консервативно. Агенту предписано не выдумывать отсутствующие данные, отличать подтверждённый опыт от заявленных самостоятельно навыков, переводить и нормализовать текст на итальянский язык и добавлять заметки об извлечении всякий раз, когда поле неоднозначно, выведено или отсутствует. Например, удостоверение водителя погрузчика, сертификат HACCP или водительское удостоверение могут рассматриваться как квалификация, доступная для поиска, тогда как курс без соответствующего опыта работы фиксируется с большей осторожностью. Это делает результат полезным для рекрутинга, а не просто извлечением текста.
Каждое разобранное резюме получает оценку extraction_confidence от 0 до 1. В интерфейсе это превращается в систему качества по принципу светофора: отличное, хорошее, удовлетворительное, плохое или очень плохое извлечение. Документы низкого качества могут быть отклонены до сохранения, тогда как пригодные документы показываются оператору или кандидату на экране проверки, где извлечённые поля можно исправить перед сохранением. Система также фиксирует заметки об извлечении, определяет, содержит ли резюме фотографию кандидата, нормализует адреса по итальянским административным единицам и выполняет геокодирование местоположений через Google Maps для географического сопоставления.
После того как резюме преобразовано в структурированные данные, оно питает слой поиска, спроектированный специально для рекрутинга. Вместо генерации одного универсального эмбеддинга для всего кандидата платформа группирует полезную информацию в четыре семантических поисковых блока: роли и навыки, опыт работы, местоположение и личные/рабочие характеристики. Эти фрагменты объединяют данные резюме с последующими операционными сигналами, такими как заметки собеседований, оценки консультантов, оценки твёрдых навыков и наблюдения за мягкими навыками.
Это создаёт слой сопоставления в стиле RAG для расширенного поиска. Google Vertex gemini-embedding-2 генерирует 3072-мерные эмбеддинги для каждого семантического блока, хранящиеся в PostgreSQL/pgvector в виде оптимизированных векторов с индексами HNSW. Затем рекрутеры могут искать на естественном языке, а система отдельно сравнивает разные измерения: релевантность роли, уровень, географическое соответствие и контекстные ограничения. Результат — это не поиск по ключевым словам по загруженным PDF, а структурированный индекс талантов, построенный из разнородных документов, проверки человеком и обогащённых AI знаний о рекрутинге.
Показанные скриншоты анонимизированы: реальные имена кандидатов, контакты и детали резюме заменены вымышленными данными.
Галерея