ClickRisorse
採用プラットフォーム
2025 - now · プロダクトエンジニアリングとAIワークフロー設計
HRコンサルティング向けの採用プラットフォーム — 公開求人ボードとコンサルタント向けバックオフィスを備え、SupabaseとpgvectorのスタックでAIによるCV解析とセマンティック候補者検索を実現。
ClickRisorse:HRコンサルティングをデータ駆動型の採用プラットフォームへ
ClickRisorseは、採用を運任せではなく方法論として提示します。適切な人材は、継続的なサポート、構造化された評価、そして専任のHRアドバイザーを通じて選ばれます。ClickRisorse向けに構築されたプラットフォームは、その約束を候補者、企業、コンサルタント、内部管理者のための完全なデジタルオペレーティングシステムへと翻訳します。
このプロジェクトは、Vue 3、Vite、TypeScript、Tailwind CSS v4、Pinia、Vue Routerで構築されたTurboRepoモノレポです。公開求人ボードの体験と内部管理ダッシュボードを分離しつつ、Fluent UIのラッパー、再利用可能なVueコンポーネント、デザイントークン、ドメインに依存しないフォームコントロールに基づく共通のUIライブラリを共有します。
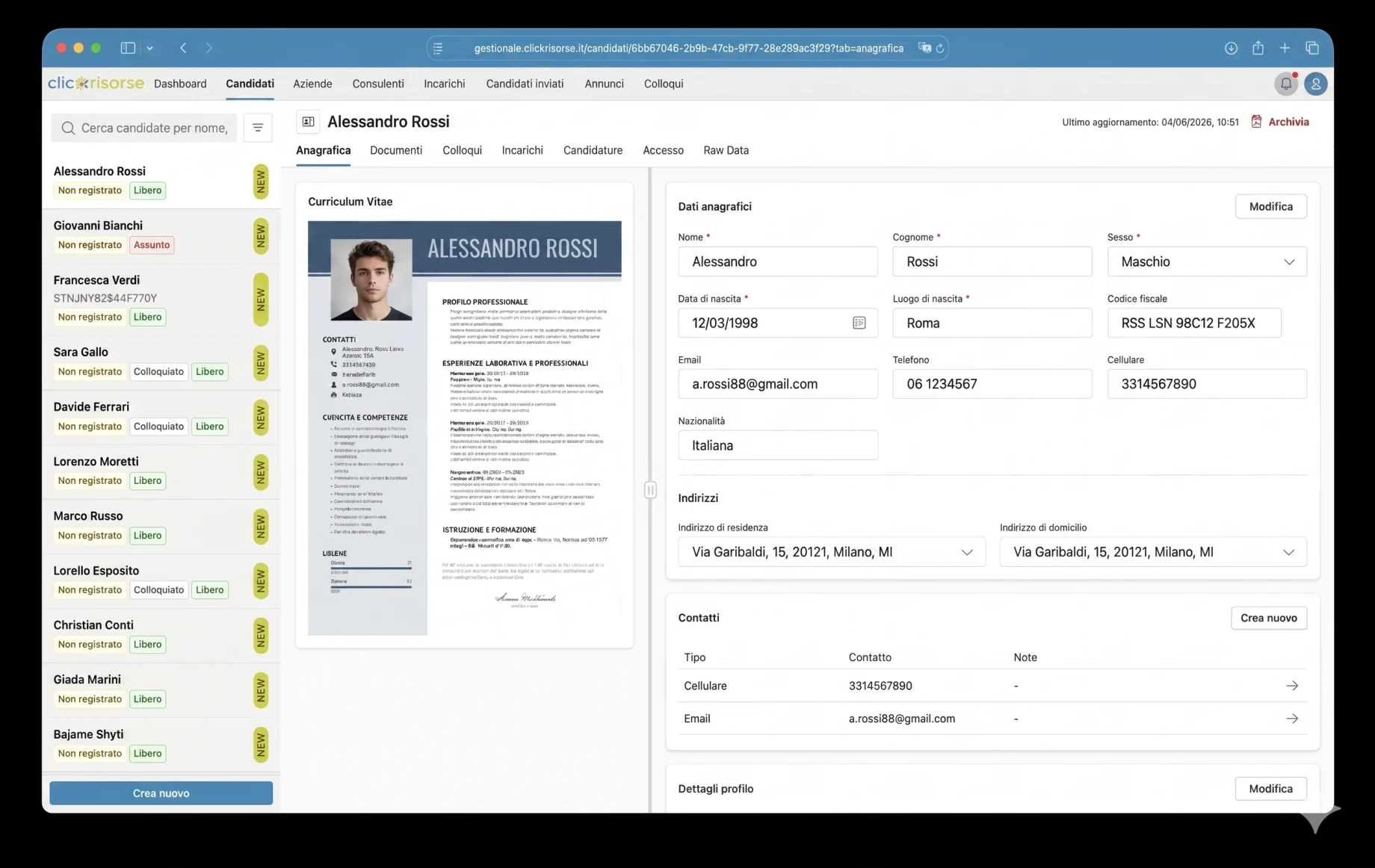
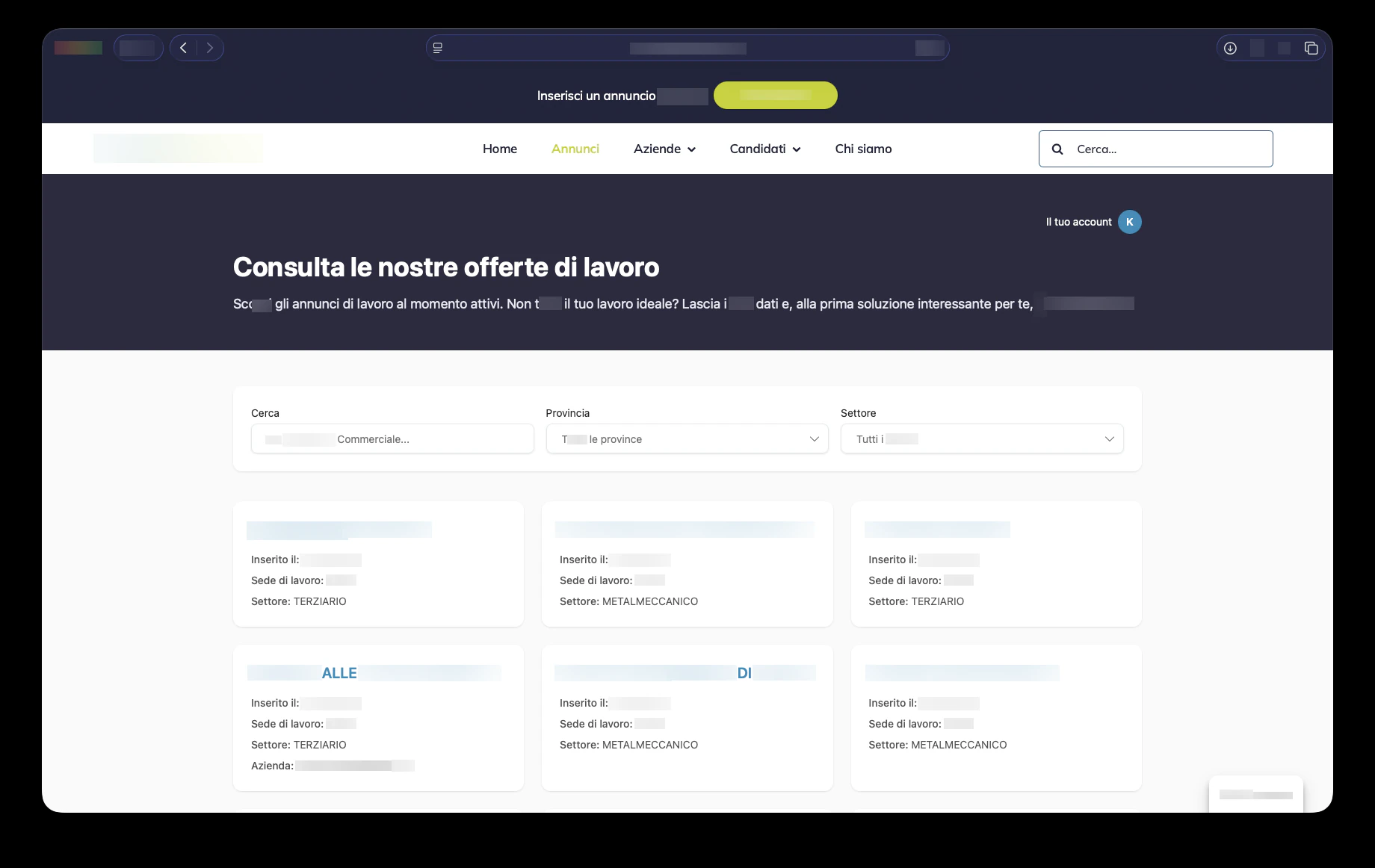
公開側では、候補者はアクティブな求人を閲覧し、検索語・県・業種で絞り込み、詳細な求人ページを開いて段階的なフローで応募できます。応募プロセスはCVのアップロード、メール認証、Cloudflare Turnstileによるボット対策、プライバシー同意、プロフィールの再利用に対応しています。CVがアップロードされると、システムは構造化された情報を抽出し、候補者がデータを確認できるようにし、将来の機会に備えてプロフィールを保存します。これはClickRisorseの公式の約束を直接支えています。すなわち、一度の登録で多数の応募ができ、適した機会が現れた際にCVが再送されるというものです。
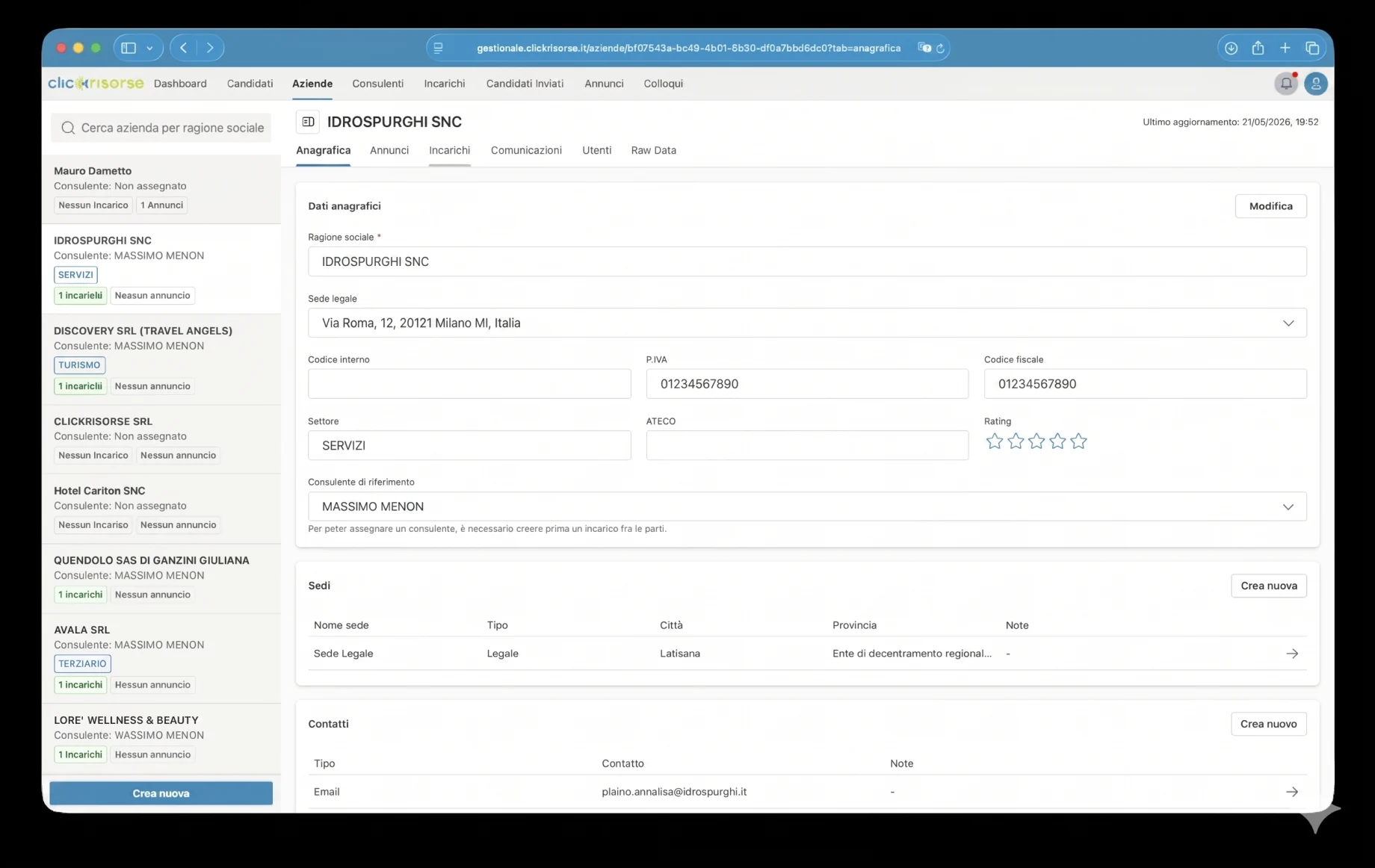
企業向けには、プラットフォームはアカウント作成、VAT番号の検証、住所の選択、複数の企業拠点、ロールベースの企業ユーザーをサポートします。また求人掲載のワークフローにも接続し、シンプルで自律的な求人掲載と候補者管理というClickRisorseの公開された提供価値に合致します。
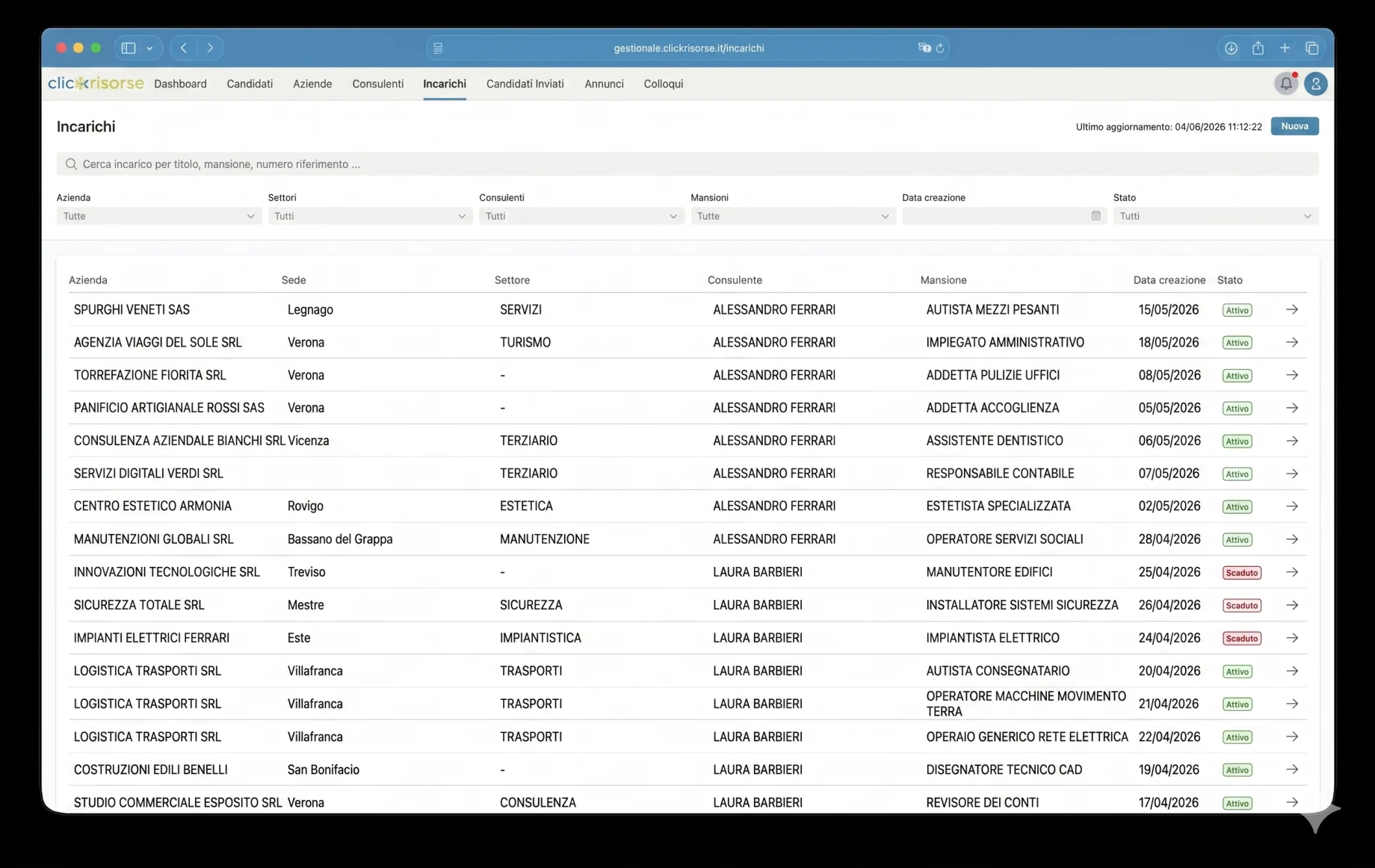
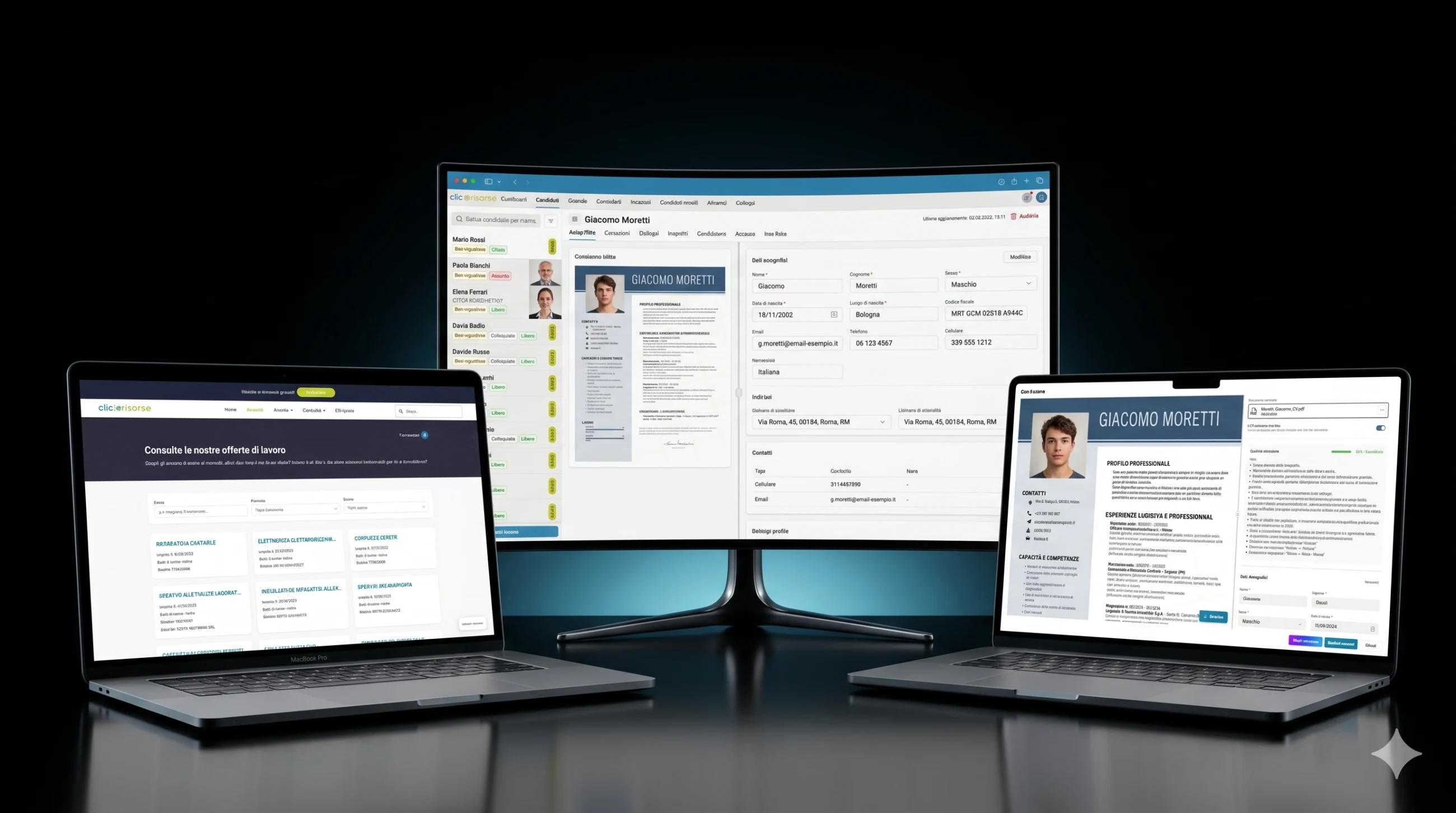
内部ダッシュボードこそ、プラットフォームが運用の場となる場所です。管理者とコンサルタントは、密度の高いテーブル、ドロワー、ダイアログのインターフェースを通じて、候補者、企業、コンサルタント、ユーザー、求人広告、案件、面接、コミュニケーション、送付済み候補者を管理します。ナビゲーションはロール対応です。企業は自社のエリアを見て、コンサルタントは割り当てられた運用ビューにアクセスし、管理者はシステム全体を制御します。KPIカード、売上チャート、未読コミュニケーションのバッジ、フィルタリングされたリストにより、ダッシュボードは時折のバックオフィス利用ではなく日々の採用業務に適したものになっています。
技術的な中核はSupabaseです。PostgreSQL、Auth、Storage、Row Level Security、生成されたデータベース型、Deno Edge Functions。スキーマはプロフィール、ロール、権限、企業、企業拠点、コンサルタント、候補者、求人掲載、案件、面接、ドキュメント、応募、通知、検索実行をモデル化します。アクセスはRBACとRLSによって統制され、候補者は自身のプロフィールに限定され、内部の候補者データは管理者とコンサルタントに限定されます。
AIは運用業務を改善する箇所に統合されています。CV解析はGoogle Vertex AI/Geminiを使用して、PDFファイルから候補者データ、職務経験、資格、言語、連絡先を抽出します。セマンティックな候補者検索は、OpenAIの埋め込み、pgvector、HNSWインデックス、そして職種・経験・所在地・特性にまたがるマルチ埋め込みスコアリングを使用します。AIアシスタントは、UIを技術的なパラメータではなくビジネス用語に集中させたまま、コンサルタントが自然言語で候補者を検索するのを支援します。
深いAIレイヤー:多様なCVを読み取り、検索可能なタレントデータへ変換する
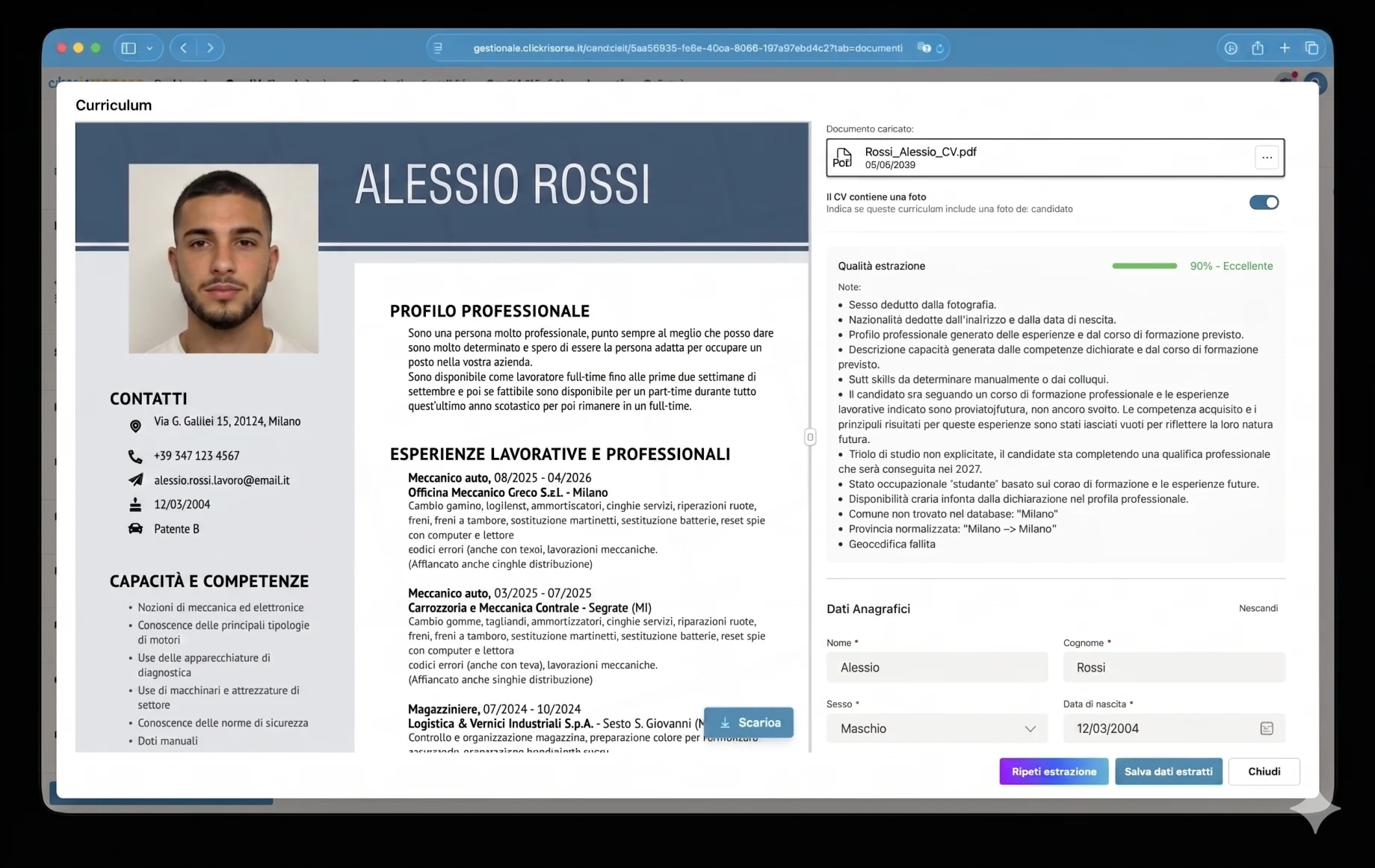
プラットフォームの最も複雑な部分の一つは、候補者のCVを中心に構築されたAIレイヤーです。履歴書は標準化された文書ではありません。すべてのPDFは、構造、視覚的な階層、言語、詳細度、品質が異なる状態で届きます。きれいなデジタルファイルもあれば、スキャンされた文書もあります。表、写真、ロゴ、欠落した日付、一貫性のない職種名、あるいは実際の職務経験に裏付けられていない自己申告のスキルを含むものもあります。
これを解決するために、プラットフォームは汎用的なアップロードフォームではなく、ドメインに最適化された抽出パイプラインを使用します。CVは、HR志向の厳格なプロンプト、構造化された出力スキーマ、検証ルールで構築された専用のAIエージェントによって処理されます。パーサーはネイティブなPDF理解とOCRにGoogle Vertex AI / Geminiを使用し、データを正規化された候補者モデルへ抽出します。個人情報、連絡先、職業プロフィール、ハードスキル、職務経験、学歴、資格、言語、職務上の希望、就業可能性、移動可能性、保護対象カテゴリーの情報です。
抽出は意図的に保守的です。エージェントには、欠落したデータを作り出さないこと、実証された経験と自己申告のスキルを区別すること、テキストをイタリア語に翻訳して正規化すること、そしてフィールドが曖昧・推測・欠落している場合には常に抽出ノートを追加することが指示されています。例えば、フォークリフトの免許、HACCP認証、運転免許証は検索可能な資格として扱える一方、対応する職務経験のない講座はより慎重に記録されます。これにより、出力は単なるテキスト抽出ではなく採用に役立つものになります。
解析された各CVには、0から1までのextraction_confidenceスコアが付与されます。これはインターフェース上で信号機のような品質システムになります。抽出は優秀、良好、まずまず、不良、または非常に不良です。低品質の文書は保存前に拒否でき、使用可能な文書は、保存前に抽出されたフィールドを修正できるレビュー画面でオペレーターまたは候補者に表示されます。システムはまた、抽出ノートを記録し、CVに候補者の写真が含まれているかを検出し、住所をイタリアの行政区分に対して正規化し、地理的マッチングのためにGoogle Mapsで所在地をジオコーディングします。
CVが構造化データへ変換されると、それは採用のために特別に設計された検索レイヤーへ供給されます。候補者全体に対して一つの汎用的な埋め込みを生成する代わりに、プラットフォームは有用な情報を4つのセマンティックな検索ブロックにグループ化します。職種とスキル、職務経験、所在地、そして個人的/職務上の特性です。これらのチャンクは、CVデータを面接ノート、コンサルタントの評価、ハードスキルのアセスメント、ソフトスキルの観察といった後続の運用シグナルと統合します。
これにより、高度な検索のためのRAG形式のマッチングレイヤーが生まれます。Google Vertexのgemini-embedding-2が各セマンティックブロックに対して3072次元の埋め込みを生成し、HNSWインデックスを備えた最適化されたベクトルとしてPostgreSQL/pgvectorに保存します。リクルーターはその後、自然言語で検索でき、システムは異なる次元を個別に比較します。職務の関連性、シニオリティ、地理的な適合性、文脈上の制約です。その結果は、アップロードされたPDFに対するキーワード検索ではなく、多様な文書、人手レビュー、AIで強化された採用知識から構築された構造化されたタレントインデックスです。
表示されているスクリーンショットは匿名化されています。実際の候補者名、連絡先、CVの詳細は架空のデータに置き換えられています。
ギャラリー