ClickRisorse
Piattaforma di recruiting
2025 - now · Product engineering e architettura dei workflow AI
Piattaforma di recruiting per la consulenza HR — una bacheca annunci pubblica e un back-office per consulenti, con parsing AI dei CV e ricerca semantica dei candidati su uno stack Supabase e pgvector.
ClickRisorse: trasformare la consulenza HR in una piattaforma di recruiting data-driven
ClickRisorse presenta il recruiting come un metodo, non come una questione di fortuna: le persone giuste vengono selezionate attraverso un supporto continuo, una valutazione strutturata e un consulente HR dedicato. La piattaforma realizzata per ClickRisorse traduce questa promessa in un sistema operativo digitale completo per candidati, aziende, consulenti e amministratori interni.
Il progetto è un monorepo TurboRepo realizzato con Vue 3, Vite, TypeScript, Tailwind CSS v4, Pinia e Vue Router. Separa l’esperienza pubblica della bacheca annunci dalla dashboard di gestione interna, condividendo al contempo una libreria UI comune basata su wrapper di Fluent UI, componenti Vue riutilizzabili, design token e controlli di form indipendenti dal dominio.
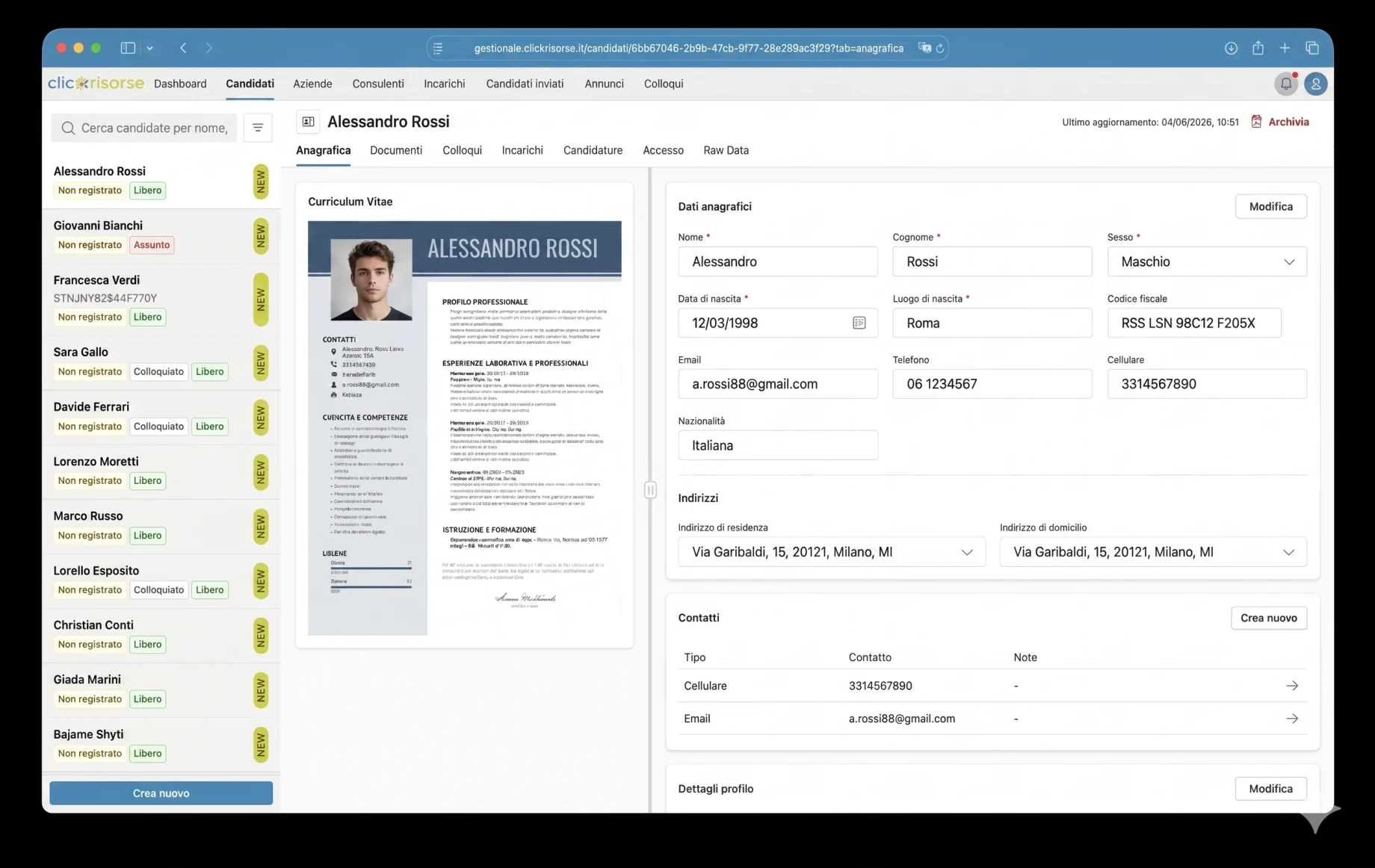
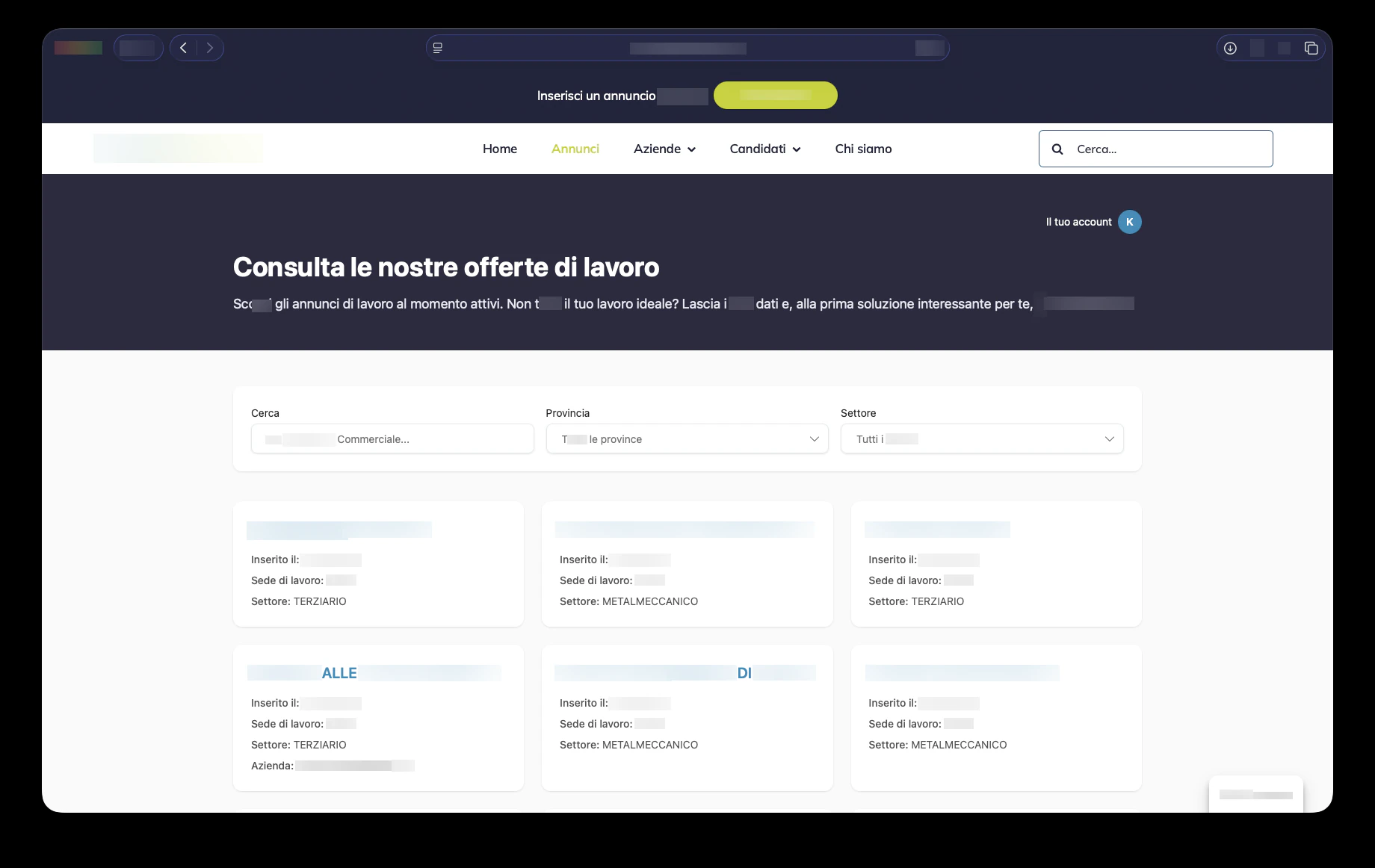
Sul lato pubblico, i candidati possono sfogliare le offerte di lavoro attive, filtrare per termine di ricerca, provincia e settore, aprire una pagina di dettaglio dell’annuncio e candidarsi tramite un flusso progressivo. Il processo di candidatura supporta il caricamento del CV, la verifica dell’email, la protezione anti-bot Cloudflare Turnstile, il consenso privacy e il riutilizzo del profilo. Una volta caricato il CV, il sistema estrae le informazioni strutturate, consente al candidato di rivedere i dati e conserva il profilo per opportunità future. Questo supporta direttamente la promessa ufficiale di ClickRisorse: una registrazione, molte candidature, con il CV inviato nuovamente quando si presenta un’opportunità adatta.
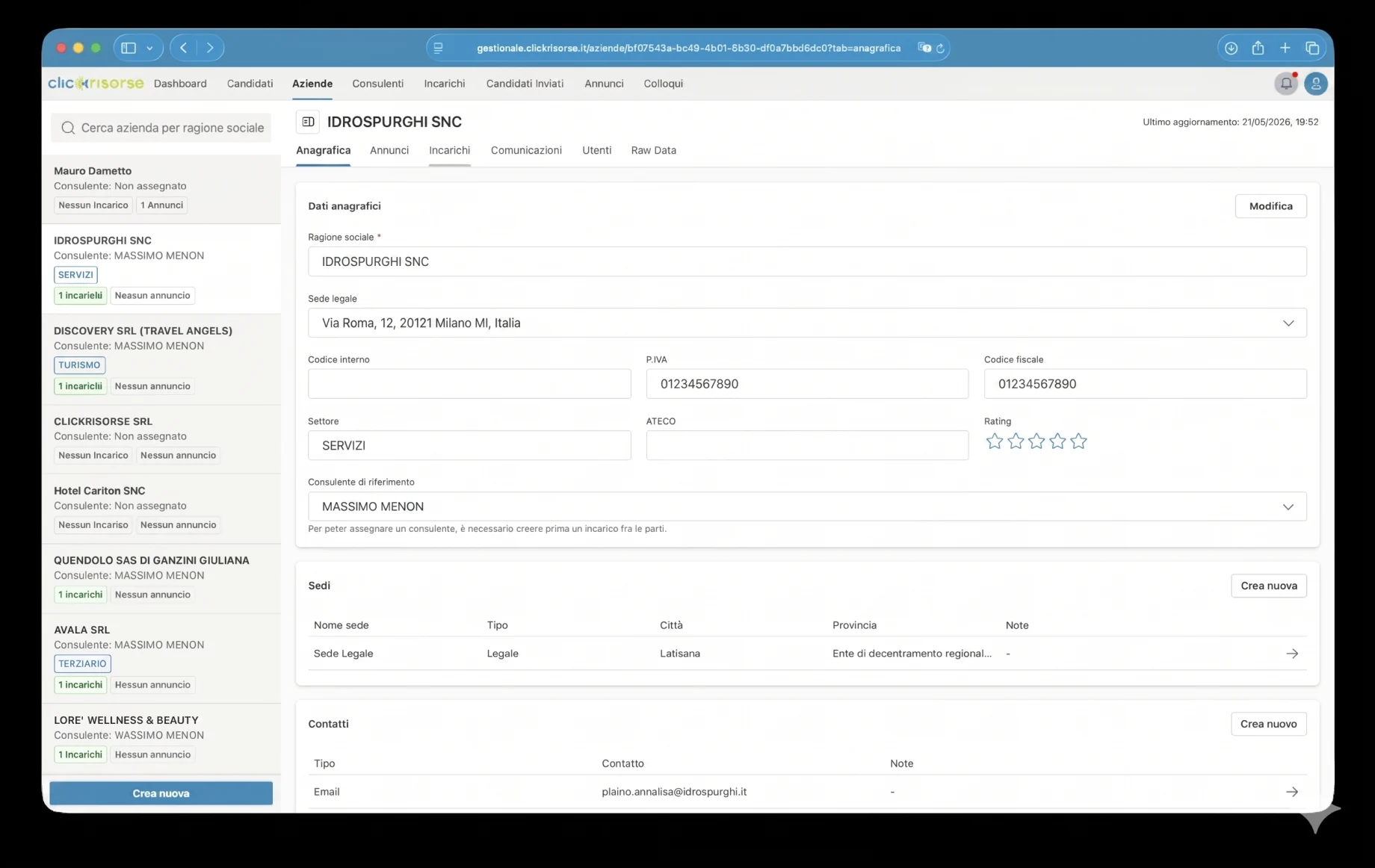
Per le aziende, la piattaforma supporta la creazione dell’account, la validazione della partita IVA, la selezione dell’indirizzo, più sedi aziendali e utenti aziendali basati su ruoli. Si collega inoltre ai workflow di pubblicazione degli annunci, in linea con l’offerta pubblica di ClickRisorse di una pubblicazione degli annunci e gestione dei candidati semplice e autonoma.
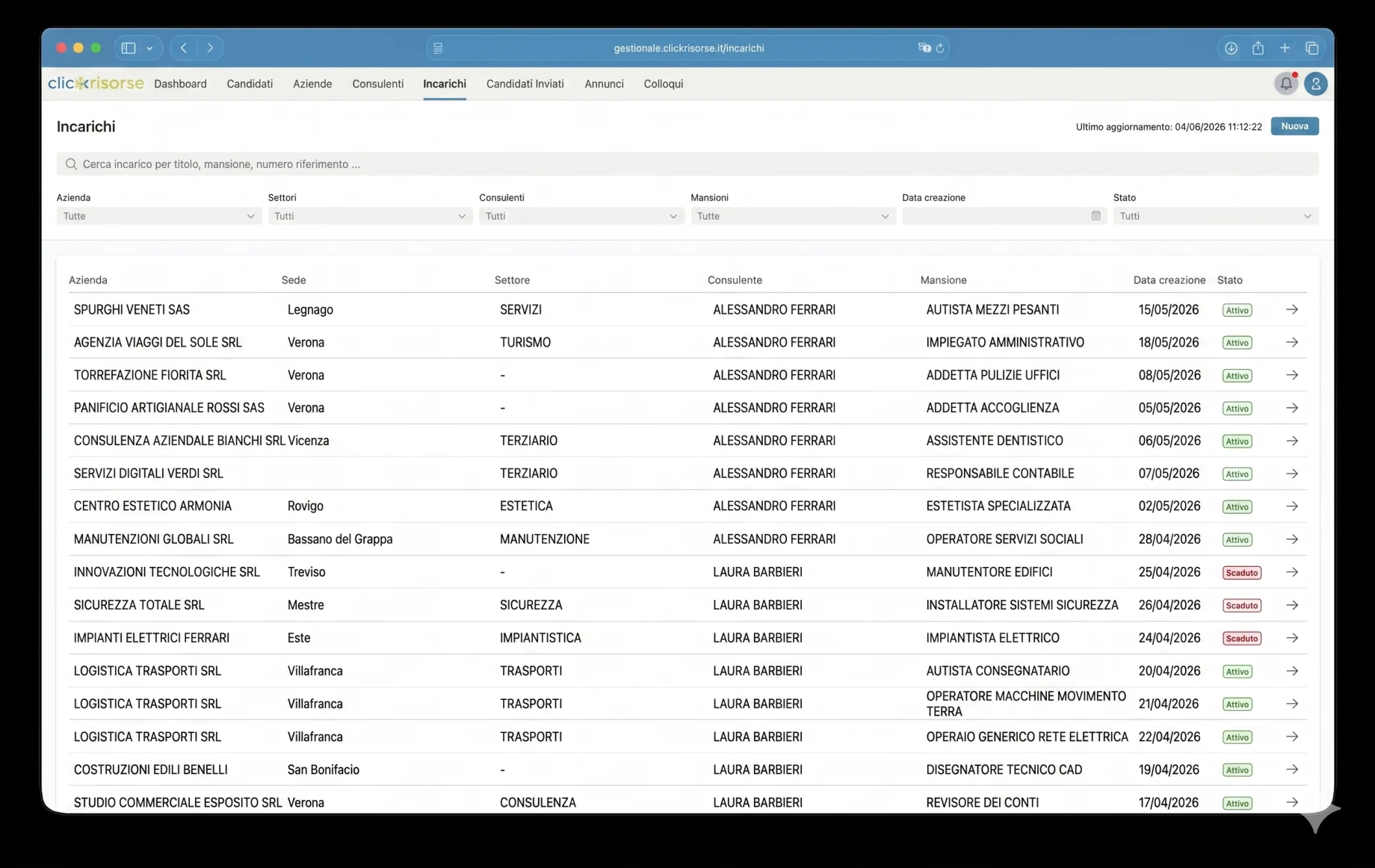
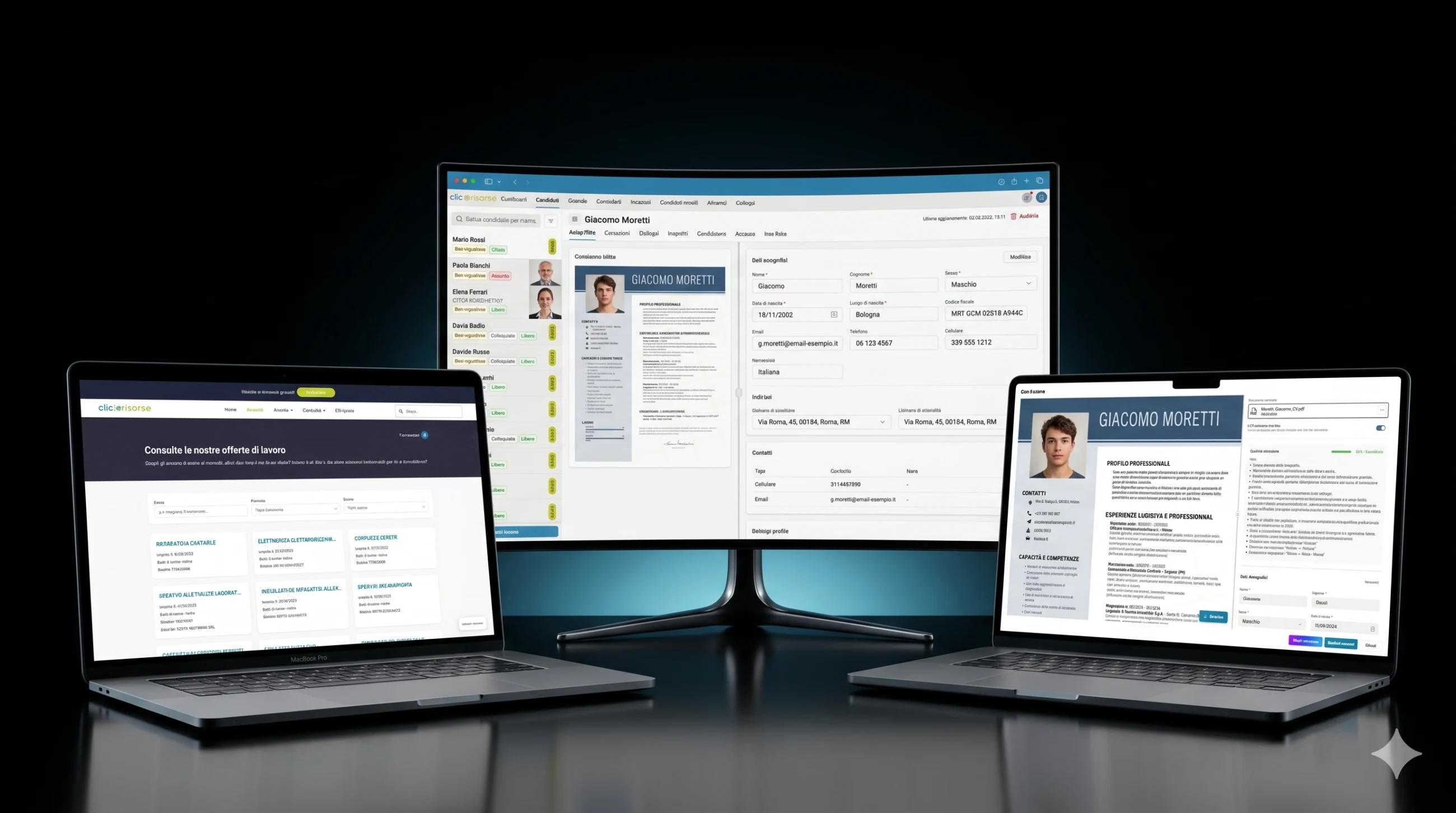
La dashboard interna è il punto in cui la piattaforma diventa operativa. Amministratori e consulenti gestiscono candidati, aziende, consulenti, utenti, annunci di lavoro, incarichi, colloqui, comunicazioni e candidati inviati attraverso interfacce dense di tabelle, drawer e dialog. La navigazione è consapevole dei ruoli: le aziende vedono le proprie aree, i consulenti accedono alle viste operative assegnate e gli amministratori controllano l’intero sistema. Card KPI, grafici dei ricavi, badge delle comunicazioni non lette ed elenchi filtrati rendono la dashboard adatta alle operazioni quotidiane di recruiting anziché a un uso saltuario di back-office.
Il nucleo tecnico è Supabase: PostgreSQL, Auth, Storage, Row Level Security, tipi di database generati e Deno Edge Functions. Lo schema modella profili, ruoli, permessi, aziende, sedi aziendali, consulenti, candidati, annunci di lavoro, incarichi, colloqui, documenti, candidature, notifiche ed esecuzioni di ricerca. L’accesso è governato tramite RBAC e RLS, con i candidati limitati ai propri profili e i dati interni dei candidati riservati ad amministratori e consulenti.
L’AI è integrata dove migliora il lavoro operativo. Il parsing dei CV usa Google Vertex AI/Gemini per estrarre dai file PDF i dati del candidato, l’esperienza lavorativa, le qualifiche, le lingue e i contatti. La ricerca semantica dei candidati usa embedding OpenAI, pgvector, indici HNSW e scoring multi-embedding su ruoli, esperienza, località e caratteristiche. Un assistente AI aiuta i consulenti a cercare i candidati in linguaggio naturale mantenendo l’interfaccia focalizzata su termini di business, non su parametri tecnici.
Strato AI profondo: leggere CV eterogenei e trasformarli in dati sui talenti ricercabili
Una delle parti più complesse della piattaforma è lo strato AI costruito attorno ai CV dei candidati. Un curriculum non è un documento standardizzato: ogni PDF arriva con una struttura, una gerarchia visiva, una lingua, un livello di dettaglio e una qualità diversi. Alcuni sono file digitali puliti, altri sono documenti scansionati; alcuni includono tabelle, foto, loghi, date mancanti, qualifiche professionali incoerenti o competenze autodichiarate che non sono supportate da un’effettiva esperienza lavorativa.
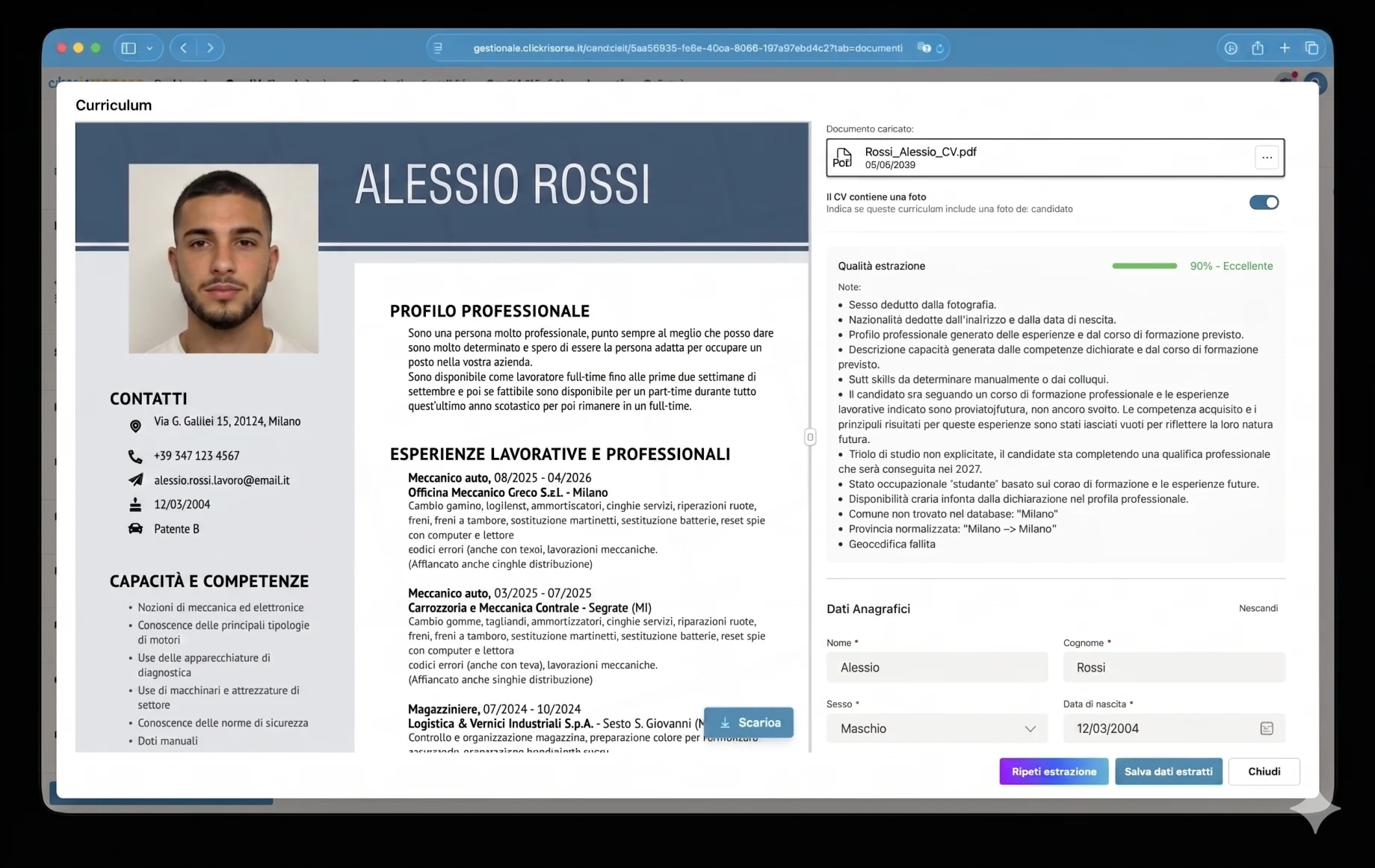
Per risolvere questo, la piattaforma usa una pipeline di estrazione ottimizzata per il dominio anziché un generico form di caricamento. I CV vengono elaborati da agenti AI specializzati costruiti con prompt rigorosi orientati all’HR, schemi di output strutturati e regole di validazione. Il parser usa Google Vertex AI / Gemini per la comprensione nativa dei PDF e l’OCR, estraendo i dati in un modello normalizzato del candidato: dati personali, contatti, profilo professionale, hard skill, esperienza lavorativa, formazione, certificazioni, lingue, preferenze lavorative, disponibilità, mobilità e informazioni sulle categorie protette.
L’estrazione è deliberatamente conservativa. All’agente viene chiesto di non inventare dati mancanti, di distinguere l’esperienza comprovata dalle competenze autodichiarate, di tradurre e normalizzare il testo in italiano e di aggiungere note di estrazione ogni volta che un campo è ambiguo, dedotto o mancante. Ad esempio, un patentino per il muletto, una certificazione HACCP o una patente di guida possono essere trattati come una qualifica ricercabile, mentre un corso senza un’esperienza lavorativa corrispondente viene registrato con maggiore cautela. Questo rende l’output utile per il recruiting, non solo un’estrazione di testo.
Ogni CV elaborato riceve un punteggio extraction_confidence da 0 a 1. Questo diventa un sistema di qualità a semaforo nell’interfaccia: estrazione eccellente, buona, discreta, scarsa o molto scarsa. I documenti di bassa qualità possono essere rifiutati prima dell’archiviazione, mentre i documenti utilizzabili vengono mostrati all’operatore o al candidato in una schermata di revisione dove i campi estratti possono essere corretti prima del salvataggio. Il sistema registra anche le note di estrazione, rileva se il CV include una foto del candidato, normalizza gli indirizzi rispetto alle suddivisioni amministrative italiane e geocodifica le località tramite Google Maps per il matching geografico.
Una volta che il CV è trasformato in dati strutturati, alimenta uno strato di retrieval progettato specificamente per il recruiting. Anziché generare un singolo embedding generico per l’intero candidato, la piattaforma raggruppa le informazioni utili in quattro blocchi semantici di retrieval: ruoli e competenze, esperienza lavorativa, località e caratteristiche personali/lavorative. Questi chunk aggregano i dati del CV con segnali operativi successivi come note dei colloqui, valutazioni dei consulenti, assessment delle hard skill e osservazioni sulle soft skill.
Questo crea uno strato di matching in stile RAG per la ricerca avanzata. Google Vertex gemini-embedding-2 genera embedding a 3072 dimensioni per ogni blocco semantico, archiviati in PostgreSQL/pgvector come vettori ottimizzati con indici HNSW. I recruiter possono quindi cercare in linguaggio naturale, mentre il sistema confronta separatamente diverse dimensioni: pertinenza del ruolo, seniority, adeguatezza geografica e vincoli contestuali. Il risultato non è una ricerca per parole chiave sui PDF caricati, ma un indice strutturato dei talenti costruito a partire da documenti eterogenei, revisione umana e conoscenza di recruiting arricchita dall’AI.
Gli screenshot mostrati sono anonimizzati: nomi reali dei candidati, contatti e dettagli dei CV sono stati sostituiti con dati fittizi.
Galleria